第 9 章 解析 (Parsing)
JDBC 客户端将 SQL 语句作为字符串提交给数据库引擎。引擎必须从这个字符串中提取必要的信息来创建查询树。这种提取过程有两个阶段:基于语法的阶段,称为解析 (parsing);以及基于语义的阶段,称为规划 (planning)。本章介绍解析。规划将在第 10 章中介绍。
9.1 语法与语义 (Syntax Versus Semantics)
语言的语法 (syntax) 是一组规则,描述了可能构成有意义语句的字符串。例如,考虑以下字符串:
select from tables T1 and T2 where b - 3
这个字符串在语法上不合法有几个原因:
select子句必须包含内容。- 标识符
tables不是关键字,将被视为表名。 - 表名之间需要用逗号分隔,而不是关键字
and。 - 字符串 “b - 3” 不表示谓词。
这些问题中的每一个都导致这个字符串作为 SQL 语句完全没有意义。无论标识符 tables、T1、T2 和 b 实际表示什么,引擎都无法弄清楚如何执行它。
语言的语义 (semantics) 指定了语法正确的字符串的实际含义。考虑以下语法上合法的字符串:
select a from x, z where b = 3
您可以推断此语句是一个查询,它请求两个表(名为 x 和 z)中的一个字段(名为 a),并且具有谓词 b = 3。因此,该语句可能是有意义的。
该语句是否实际有意义取决于关于 x、z、a 和 b 的语义信息 (semantic information)。特别是,x 和 z 必须是表名,并且这些表必须包含一个名为 a 的字段和一个名为 b 的数字字段。这种语义信息可以从数据库的元数据 (metadata) 中确定。解析器 (parser) 对元数据一无所知,因此无法评估 SQL 语句的含义。相反,检查元数据的责任属于规划器 (planner),将在第 10 章中讨论。
9.2 词法分析 (Lexical Analysis)
解析器的首要任务是将输入字符串分解成称为标记 (tokens) 的“块”。执行此任务的解析器部分称为词法分析器 (lexical analyzer)。
每个标记都具有类型和值。SimpleDB 词法分析器支持五种标记类型:
- 单字符分隔符 (Single-character delimiters),例如逗号
, - 整数常量 (Integer constants),例如
123 - 字符串常量 (String constants),例如
'joe' - 关键字 (Keywords),例如
select、from和where - 标识符 (Identifiers),例如
STUDENT、x和glop34a
空白字符 (Whitespace characters)(空格、制表符和换行符)通常不属于标记的一部分;唯一的例外是字符串常量内部。空白的目的是增强可读性并分隔标记。
再次考虑之前的 SQL 语句:
select a from x, z where b = 3
词法分析器为其创建了十个标记,如 图 9.1 所示。
图 9.1 词法分析器生成的标记 (Tokens produced by the lexical analyzer)
| 类型 | 值 |
| ------------- | -------- |
| keyword | select |
| identifier | a |
| keyword | from |
| identifier | x |
| delimiter | , |
| identifier | z |
| keyword | where |
| identifier | b |
| delimiter | = |
| intconstant | 3 |
从概念上讲,词法分析器的行为很简单——它一次读取一个字符的输入字符串,当它确定下一个标记已被读取时停止。词法分析器的复杂性与标记类型的集合成正比:要查找的标记类型越多,实现就越复杂。
Java 提供了两种不同的内置标记器(它们对词法分析器的术语):一个在 StringTokenizer 类中,另一个在 StreamTokenizer 类中。StringTokenizer 更简单易用,但它只支持两种类型的标记:分隔符和单词(即分隔符之间的子字符串)。这不适用于 SQL,特别是由于 StringTokenizer 不理解数字或带引号的字符串。另一方面,StreamTokenizer 具有广泛的标记类型集,包括支持 SimpleDB 使用的所有五种类型。
图 9.2 给出了 TokenizerTest 类的代码,它演示了 StreamTokenizer 的用法。代码对给定的一行输入进行标记化,并打印每个标记的类型和值。
tok.ordinaryChar('.') 调用告诉标记器将句点解释为分隔符。(尽管 SimpleDB 中不使用句点,但将其标识为分隔符很重要,以防止它们被接受为标识符的一部分。)相反,tok.wordChars('_', '_') 调用告诉标记器将下划线解释为标识符的一部分。tok.lowerCaseMode(true) 调用告诉标记器将所有字符串标记(但不包括带引号的字符串)转换为小写,这使得 SQL 对关键字和标识符不区分大小写。
nextToken 方法将标记器定位在流中的下一个标记处;返回值为 TT_EOF 表示没有更多标记。标记器的公共变量 ttype 保存当前标记的类型。值 TT_NUMBER 表示数字常量,TT_WORD 表示标识符或关键字,单引号的整数表示表示字符串常量。单字符分隔符标记的类型是该字符的整数表示。
图 9.2 TokenizerTest 类 (The class TokenizerTest)
import java.io.*;
import java.util.*;
public class TokenizerTest {
// 预定义的关键字集合
private static Collection<String> keywords =
Arrays.asList("select", "from", "where", "and", "insert",
"into", "values", "delete", "update", "set",
"create", "table", "int", "varchar", "view", "as",
"index", "on");
public static void main(String[] args) throws IOException {
String s = getStringFromUser(); // 从用户获取输入字符串
StreamTokenizer tok = new StreamTokenizer(new StringReader(s)); // 使用 StreamTokenizer 处理字符串
tok.ordinaryChar('.'); // 将句点视为普通字符(即分隔符,不属于单词)
tok.wordChars('_', '_'); // 将下划线视为单词的一部分
tok.lowerCaseMode(true); // 将标识符和关键字转换为小写
// 循环直到文件结束
while (tok.nextToken() != StreamTokenizer.TT_EOF) {
printCurrentToken(tok); // 打印当前标记的信息
}
}
// 从用户获取一行输入
private static String getStringFromUser() {
System.out.println("Enter tokens:");
Scanner sc = new Scanner(System.in);
String s = sc.nextLine();
sc.close();
return s;
}
// 打印当前标记的类型和值
private static void printCurrentToken(StreamTokenizer tok) throws IOException {
if (tok.ttype == StreamTokenizer.TT_NUMBER) {
System.out.println("IntConstant " + (int) tok.nval); // 如果是数字,打印整数常量
} else if (tok.ttype == StreamTokenizer.TT_WORD) {
String word = tok.sval;
if (keywords.contains(word)) {
System.out.println("Keyword " + word); // 如果是预定义关键字,打印关键字
} else {
System.out.println("Id " + word); // 否则,打印标识符
}
} else if (tok.ttype == '\'') {
System.out.println("StringConstant " + tok.sval); // 如果是单引号,打印字符串常量
} else {
System.out.println("Delimiter " + (char) tok.ttype); // 否则,打印分隔符
}
}
}
9.3 SimpleDB的词法分析器 (The SimpleDB Lexical Analyzer)
StreamTokenizer 类是一个通用词法分析器,但使用起来可能很笨拙。SimpleDB 的 Lexer 类提供了一种更简单的方式供解析器访问标记流。解析器可以调用两种方法:查询当前标记信息的方法,以及告诉词法分析器“消费”当前标记(返回其值并移动到下一个标记)的方法。每种标记类型都有一对相应的方法。这些十个方法的 API 如 图 9.3 所示。
前五个方法返回有关当前标记的信息。matchDelim 方法如果当前标记是具有指定值的分隔符,则返回 true。类似地,matchKeyword 方法如果当前标记是具有指定值的关键字,则返回 true。其他三个 matchXXX 方法如果当前标记是正确类型,则返回 true。
后五个方法“消费”当前标记。每个方法都调用其相应的 matchXXX 方法。如果该方法返回 false,则抛出异常;否则,下一个标记变为当前标记。此外,eatIntConstant、eatStringConstant 和 eatId 方法返回当前标记的值。
图 9.3 SimpleDB 词法分析器的 API (The API for the SimpleDB lexical analyzer)
Lexer
public boolean matchDelim(char d);// 检查是否是指定分隔符public boolean matchIntConstant();// 检查是否是整数常量public boolean matchStringConstant();// 检查是否是字符串常量public boolean matchKeyword(String w);// 检查是否是指定关键字public boolean matchId();// 检查是否是标识符public void eatDelim(char d);// 消费指定分隔符public int eatIntConstant();// 消费整数常量并返回其值public String eatStringConstant();// 消费字符串常量并返回其值public void eatKeyword(String w);// 消费指定关键字public String eatId();// 消费标识符并返回其值
图 9.4 中的 LexerTest 类演示了这些方法的用法。代码读取输入行。它期望每行都是 “A = c” 或 “c = A” 的形式,其中 A 是标识符,c 是整数常量。任何其他形式的输入行都会生成异常。
Lexer 的代码如 图 9.5 所示。其构造函数设置了流标记器。eatIntConstant、eatStringConstant 和 eatId 方法返回当前标记的值。initKeywords 方法构造了 SimpleDB 版本 SQL 中使用的关键字集合。
图 9.4 LexerTest 类 (The class LexerTest)
import java.util.Scanner;
public class LexerTest {
public static void main(String[] args) {
String x = "";
int y = 0;
Scanner sc = new Scanner(System.in);
while (sc.hasNext()) { // 循环读取用户输入行
String s = sc.nextLine();
Lexer lex = new Lexer(s); // 为每行创建一个新的 Lexer 实例
if (lex.matchId()) { // 检查是否以标识符开头 (例如 "id = 123")
x = lex.eatId(); // 消费并获取标识符
lex.eatDelim('='); // 消费等号分隔符
y = lex.eatIntConstant(); // 消费并获取整数常量
} else { // 否则,期望以整数常量开头 (例如 "123 = id")
y = lex.eatIntConstant(); // 消费并获取整数常量
lex.eatDelim('='); // 消费等号分隔符
x = lex.eatId(); // 消费并获取标识符
}
System.out.println(x + " equals " + y); // 打印结果
}
sc.close();
}
}
图 9.5 SimpleDB Lexer 类的代码 (The code for the SimpleDB class Lexer)
import java.io.*;
import java.util.*;
public class Lexer {
private Collection<String> keywords;
private StreamTokenizer tok;
public Lexer(String s) {
initKeywords(); // 初始化关键字集合
tok = new StreamTokenizer(new StringReader(s)); // 创建 StreamTokenizer
tok.ordinaryChar('.'); // 将句点视为普通字符 (分隔符)
tok.wordChars('_', '_'); // 将下划线视为单词字符
tok.lowerCaseMode(true); // 将标识符和关键字转换为小写
nextToken(); // 初始化时读取第一个标记
}
// --- 检查当前标记状态的方法 ---
// 检查当前标记是否是指定分隔符
public boolean matchDelim(char d) {
return d == (char) tok.ttype;
}
// 检查当前标记是否是整数常量
public boolean matchIntConstant() {
return tok.ttype == StreamTokenizer.TT_NUMBER;
}
// 检查当前标记是否是字符串常量 (通过检查其类型是否为单引号的ASCII值)
public boolean matchStringConstant() {
return '\'' == (char) tok.ttype;
}
// 检查当前标记是否是指定关键字
public boolean matchKeyword(String w) {
// 必须是单词类型且其值等于指定关键字
return tok.ttype == StreamTokenizer.TT_WORD && tok.sval.equals(w);
}
// 检查当前标记是否是标识符 (是单词类型但不是关键字)
public boolean matchId() {
return tok.ttype == StreamTokenizer.TT_WORD && !keywords.contains(tok.sval);
}
// --- “消费”当前标记的方法 ---
// 消费指定分隔符
public void eatDelim(char d) {
if (!matchDelim(d)) // 如果不匹配,抛出语法错误
throw new BadSyntaxException();
nextToken(); // 移动到下一个标记
}
// 消费整数常量并返回其值
public int eatIntConstant() {
if (!matchIntConstant())
throw new BadSyntaxException();
int i = (int) tok.nval; // 获取整数值
nextToken();
return i;
}
// 消费字符串常量并返回其值
public String eatStringConstant() {
if (!matchStringConstant())
throw new BadSyntaxException();
String s = tok.sval; // 获取字符串值
nextToken();
return s;
}
// 消费指定关键字
public void eatKeyword(String w) {
if (!matchKeyword(w))
throw new BadSyntaxException();
nextToken();
}
// 消费标识符并返回其值
public String eatId() {
if (!matchId())
throw new BadSyntaxException();
String s = tok.sval; // 获取标识符值
nextToken();
return s;
}
// 读取下一个标记
private void nextToken() {
try {
tok.nextToken(); // 调用 StreamTokenizer 的 nextToken
} catch (IOException e) {
throw new BadSyntaxException(); // 将 IOException 转换为 BadSyntaxException
}
}
// 初始化 SimpleDB SQL 的关键字集合
private void initKeywords() {
keywords = Arrays.asList("select", "from", "where", "and", "insert",
"into", "values", "delete", "update", "set", "create", "table",
"varchar", "int", "view", "as", "index", "on");
}
}
StreamTokenizer 的 nextToken 方法会抛出 IOException。Lexer 的 nextToken 方法将此异常转换为 BadSyntaxException,该异常会传递回客户端(并转换为 SQLException,如第 11 章所述)。
9.4 语法 (Grammars)
语法 (grammar) 是一组规则,描述了标记如何合法地组合。以下是一个语法规则的示例:
<Field> := IdTok
语法规则的左侧指定了一个句法范畴 (syntactic category)。句法范畴表示语言中的特定概念。在上述规则中,<Field> 表示字段名的概念。语法规则的右侧是一个模式 (pattern),它指定了属于该句法范畴的字符串集合。在上述规则中,模式就是 IdTok,它匹配任何标识符标记。因此,<Field> 包含与标识符对应的字符串集合。
每个句法范畴都可以被视为其自己的小语言。例如,“SName”和“Glop”都是 <Field> 的成员。请记住,标识符不必有意义——它们只需要是标识符。因此,“Glop”是 <Field> 的一个非常好的成员,即使在 SimpleDB 大学数据库中也是如此。然而,“select”不会是 <Field> 的成员,因为它是一个关键字标记,而不是标识符标记。
语法规则右侧的模式可以包含对标记 (tokens) 和句法范畴 (syntactic categories) 的引用。具有众所周知值(即关键字和分隔符)的标记会显式出现。其他标记(标识符、整数常量和字符串常量)分别写作 IdTok、IntTok 和 StrTok。三个元字符 (meta-characters)([, ], 和 |)用作标点符号;这些字符在语言中不是分隔符,因此它们可以帮助表达模式。为了说明这一点,考虑以下四个额外的语法规则:
<Constant> := StrTok | IntTok
<Expression> := <Field> | <Constant>
<Term> := <Expression> = <Expression>
<Predicate> := <Term> [ AND <Predicate> ]
第一条规则定义了范畴 <Constant>,它代表任何常量——字符串或整数。元字符 | 表示“或”。因此,范畴 <Constant> 匹配字符串标记或整数标记,其内容(作为一种语言)将包含所有字符串常量以及所有整数常量。
第二条规则定义了范畴 <Expression>,它表示不带操作符的表达式。该规则指定表达式是字段或常量。
第三条规则定义了范畴 <Term>,它表示表达式之间简单的相等项(类似于 SimpleDB 的 Term 类)。例如,以下字符串属于 <Term>:
DeptId = DId
'math' = DName
SName = 123
65 = 'abc'
请注意,解析器不检查类型一致性;因此,后两个字符串在语法上是正确的,即使它们在语义上是不正确的。
第四条规则定义了范畴 <Predicate>,它代表项的布尔组合,类似于 SimpleDB 的 Predicate 类。元字符 [ 和 ] 表示可选内容。因此,规则的右侧匹配任何符合以下模式的标记序列:要么是一个 <Term>,要么是一个 <Term> 后跟一个 AND 关键字标记,然后(递归地)再跟一个 <Predicate>。例如,以下字符串属于 <Predicate>:
DName = 'math'
Id = 3 AND DName = 'math'
MajorId = DId AND Id = 3 AND DName = 'math'
第一个字符串是 <Term> 形式。后两个字符串是 <Term> AND <Predicate> 形式。
如果一个字符串属于特定的句法范畴,你可以画一个解析树 (parse tree) 来描绘其原因。解析树将句法范畴作为其内部节点,将标记作为其叶节点。范畴节点的子节点对应于语法规则的应用。例如,图 9.6 包含以下字符串的解析树:
DName = 'math' AND GradYear = SName
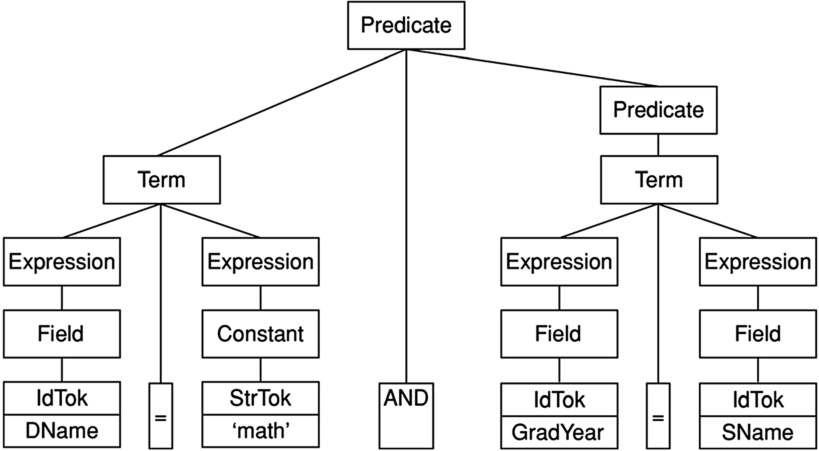
在此图中,树的叶节点出现在树的底部,以便更容易阅读输入字符串。从根节点开始,该树断言整个字符串是一个 <Predicate>,因为 “DName='math'” 是一个 <Term> ,“GradYear=SName” 是一个 <Predicate>。你可以类似地展开每个子树。例如,“DName='math'” 是一个 <Term>,因为 “DName” 和 “'math'” 都属于 <Expression>。
图 9.7 SimpleDB SQL 子集的完整语法 (The grammar for the SimpleDB subset of SQL)
<Field> := IdTok
<Constant> := StrTok | IntTok
<Expression> := <Field> | <Constant>
<Term> := <Expression> = <Expression>
<Predicate> := <Term> [ AND <Predicate> ]
<Query> := SELECT <SelectList> FROM <TableList> [ WHERE <Predicate> ]
<SelectList> := <Field> [ , <SelectList> ]
<TableList> := IdTok [ , <TableList> ]
<UpdateCmd> := <Insert> | <Delete> | <Modify> | <Create>
<Create> := <CreateTable> | <CreateView> | <CreateIndex>
<Insert> := INSERT INTO IdTok ( <FieldList> ) VALUES ( <ConstList> )
<FieldList> := <Field> [ , <FieldList> ]
<ConstList> := <Constant> [ , <ConstList> ]
<Delete> := DELETE FROM IdTok [ WHERE <Predicate> ]
<Modify> := UPDATE IdTok SET <Field> = <Expression> [ WHERE <Predicate> ]
<CreateTable> := CREATE TABLE IdTok ( <FieldDefs> )
<FieldDefs> := <FieldDef> [ , <FieldDefs> ]
<FieldDef> := IdTok <TypeDef>
<TypeDef> := INT | VARCHAR ( IntTok )
<CreateView> := CREATE VIEW IdTok AS <Query>
<CreateIndex> := CREATE INDEX IdTok ON IdTok ( <Field> )
图 9.7 列出了 SimpleDB 支持的 SQL 子集的完整语法。语法规则分为九个部分:一个部分用于常见构造,如谓词、表达式和字段;一个部分用于查询;以及七个部分用于各种类型的更新语句。
项目列表在 SQL 中经常出现。例如,在查询中,select 子句包含逗号分隔的字段列表,from 子句包含逗号分隔的标识符列表,where 子句包含 AND 分隔的项列表。每个列表都使用您在 <Predicate> 中看到的相同递归技术在语法中指定。还要注意在 <Query>、<Delete> 和 <Modify> 的规则中如何使用“可选括号”表示法,以允许它们具有可选的 where 子句。
我提到解析器不能强制执行类型兼容性,因为它无法知道它所看到标识符的类型。解析器也不能强制执行兼容的列表大小。例如,SQL insert 语句必须提及与字段名相同数量的值,但 <Insert> 的语法规则只要求字符串具有 <FieldList> 和 <ConstList>。规划器 (planner) 必须负责验证这些列表的大小相同(并且类型兼容)。
9.5 递归下降解析器 (Recursive-Descent Parsers)
解析树可以被认为是给定字符串在语法上合法的证明。但你如何确定解析树呢?数据库引擎如何判断一个字符串在语法上是否合法?
编程语言研究人员为此目的开发了许多解析算法。解析算法的复杂性通常与它能支持的语法的复杂性成正比。幸运的是,我们的 SQL 语法非常简单,因此它可以使用最简单的解析算法,即递归下降 (recursive descent)。
在基本的递归下降解析器中,每个句法范畴 (syntactic category) 都由一个 void 方法实现。调用此方法将“消费 (eat)”构成该范畴解析树的标记并返回。当标记不符合该范畴的解析树时,该方法会抛出异常。
考虑图 9.7 中构成谓词子集的 SQL 语法的前五条规则。与此语法对应的 Java 类如 图 9.8 所示。
图 9.8 简化谓词递归下降解析器的代码 (The code for a simplified recursive-descent parser for predicates)
public class PredParser {
private Lexer lex; // 词法分析器实例
public PredParser(String s) {
lex = new Lexer(s); // 构造函数初始化词法分析器
}
// 实现 <Field> := IdTok
public void field() {
lex.eatId(); // 消费一个标识符标记
}
// 实现 <Constant> := StrTok | IntTok
public void constant() {
if (lex.matchStringConstant()) { // 如果当前标记是字符串常量
lex.eatStringConstant(); // 消费字符串常量
} else { // 否则 (期望是整数常量)
lex.eatIntConstant(); // 消费整数常量
}
}
// 实现 <Expression> := <Field> | <Constant>
public void expression() {
if (lex.matchId()) { // 如果当前标记是标识符 (可能是字段)
field(); // 尝试解析一个字段
} else { // 否则 (期望是常量)
constant(); // 尝试解析一个常量
}
}
// 实现 <Term> := <Expression> = <Expression>
public void term() {
expression(); // 解析第一个表达式
lex.eatDelim('='); // 消费等号分隔符
expression(); // 解析第二个表达式
}
// 实现 <Predicate> := <Term> [ AND <Predicate> ]
public void predicate() {
term(); // 解析第一个项
if (lex.matchKeyword("and")) { // 如果当前标记是关键字 "and"
lex.eatKeyword("and"); // 消费 "and" 关键字
predicate(); // 递归调用自身解析剩余的谓词
}
}
}
考虑 field 方法,它对词法分析器进行了一次调用(并忽略任何返回值)。如果下一个标记是标识符,则调用成功返回并消费该标记。如果不是,则该方法将异常抛回给调用者。类似地,考虑 term 方法。它对 expression 的第一次调用消费了对应于单个 SQL 表达式的标记,它对 eatDelim 的调用消费了等号标记,它对 expression 的第二次调用消费了对应于另一个 SQL 表达式的标记。如果这些方法调用中的任何一个没有找到它期望的标记,它将抛出异常,term 方法将把异常传递给它的调用者。
包含备选项 (alternatives) 的语法规则使用 if 语句实现。if 语句的条件会查看当前标记,以决定做什么。举一个简单的例子,考虑 constant 方法。如果当前标记是字符串常量,则该方法消费它;否则,该方法尝试消费整数常量。如果当前标记既不是字符串常量也不是整数常量,则对 lex.eatIntConstant 的调用将生成异常。举一个不那么简单的例子,考虑 expression 方法。在这里,该方法知道如果当前标记是标识符,那么它必须查找一个字段;否则它必须查找一个常量。
predicate 方法演示了如何实现递归规则 (recursive rule)。它首先调用 term 方法,然后检查当前标记是否是关键字 AND。如果是,它会消费 AND 标记并递归调用自身。如果当前标记不是 AND,那么它知道它已经看到了列表中最后一个项并返回。因此,对 predicate 的调用将尽可能多地从标记流中消费标记——如果它看到一个 AND 标记,即使它已经看到了一个有效的谓词,它也会继续前进。
递归下降解析的有趣之处在于,方法调用的序列决定了输入字符串的解析树。练习 9.4 要求你修改每个方法的代码以打印其名称,并适当缩进;结果将类似于一个横向的解析树。
9.6 为解析器添加动作 (Adding Actions to the Parser)
基本的递归下降解析算法在输入字符串语法有效时正常返回。尽管这种行为有些有趣,但它并不是特别有用。为此,需要修改基本解析器以返回规划器所需的信息。这种修改称为为解析器添加动作 (adding actions to the parser)。
一般来说,SQL 解析器应该从 SQL 语句中提取诸如表名、字段名、谓词和常量等信息。提取的内容取决于 SQL 语句的类型:
- 对于查询 (Query):一个字段名列表(来自
select子句)、一个表名集合(来自from子句)和一个谓词(来自where子句)。 - 对于插入 (Insertion):一个表名、一个字段名列表和一个值列表。
- 对于删除 (Deletion):一个表名和一个谓词。
- 对于修改 (Modification):一个表名、要修改的字段名、一个表示新字段值的表达式和一个谓词。
- 对于表创建 (Table Creation):一个表名及其模式。
- 对于视图创建 (View Creation):一个表名及其定义。
- 对于索引创建 (Index Creation):一个索引名、一个表名和被索引字段的名称。
这些信息可以通过 Lexer 方法的返回值从标记流中提取。因此,修改每个解析器方法的策略是直接的:从对 eatId、eatStringConstant 和 eatIntConstant 的调用中获取返回值,将它们组装成一个适当的对象,并将该对象返回给方法的调用者。
图 9.9 给出了 Parser 类的代码,其方法实现了图 9.7 的语法。以下小节将详细分析这些代码。
9.6.1 解析谓词和表达式 (Parsing Predicates and Expressions)
解析器的核心部分处理定义谓词和表达式的五条语法规则,因为它们用于解析几种不同类型的 SQL 语句。Parser 中的这些方法与 PredParser(在图 9.8 中)中的方法相同,只是它们现在包含了动作并返回了值。特别是,field 方法从当前标记中获取字段名并返回它。constant、expression、term 和 predicate 方法类似,分别返回一个 Constant 对象、一个 Expression 对象、一个 Term 对象和一个 Predicate 对象。
9.6.2 解析查询 (Parsing Queries)
query 方法实现了句法范畴 <Query>。当解析器解析一个查询时,它会获取规划器所需的三个项——字段名、表名和谓词——并将它们保存在一个 QueryData 对象中。QueryData 类通过其 fields、tables 和 pred 方法使这些值可用;参见图 9.10。该类还有一个 toString 方法,用于重新创建查询字符串。在处理视图定义时将需要此方法。
图 9.9 SimpleDB Parser 类的代码 (The code for the SimpleDB class Parser)
import simpledb.query.*; // 假设包含 Predicate, Constant, Expression, Term 等类
import simpledb.record.Schema; // 假设包含 Schema 类
import java.util.*;
public class Parser {
private Lexer lex; // 词法分析器实例
public Parser(String s) {
lex = new Lexer(s); // 构造函数初始化词法分析器
}
// --- 解析谓词及其组件的方法 ---
// 实现 <Field> := IdTok
public String field() {
return lex.eatId(); // 消费并返回标识符(字段名)
}
// 实现 <Constant> := StrTok | IntTok
public Constant constant() {
if (lex.matchStringConstant()) {
return new Constant(lex.eatStringConstant()); // 消费字符串常量并返回 Constant 对象
} else {
return new Constant(lex.eatIntConstant()); // 消费整数常量并返回 Constant 对象
}
}
// 实现 <Expression> := <Field> | <Constant>
public Expression expression() {
if (lex.matchId()) {
return new Expression(field()); // 如果是标识符,解析为字段表达式
} else {
return new Expression(constant()); // 否则,解析为常量表达式
}
}
// 实现 <Term> := <Expression> = <Expression>
public Term term() {
Expression lhs = expression(); // 解析左侧表达式
lex.eatDelim('='); // 消费等号分隔符
Expression rhs = expression(); // 解析右侧表达式
return new Term(lhs, rhs); // 返回一个新的 Term 对象
}
// 实现 <Predicate> := <Term> [ AND <Predicate> ]
public Predicate predicate() {
Predicate pred = new Predicate(term()); // 解析第一个项并创建 Predicate 对象
if (lex.matchKeyword("and")) { // 如果有 "and" 关键字
lex.eatKeyword("and");
pred.conjoinWith(predicate()); // 递归解析剩余谓词并连接
}
return pred;
}
// --- 解析查询的方法 ---
// 实现 <Query> := SELECT <SelectList> FROM <TableList> [ WHERE <Predicate> ]
public QueryData query() {
lex.eatKeyword("select"); // 消费 "select" 关键字
List<String> fields = selectList(); // 解析选择列表
lex.eatKeyword("from"); // 消费 "from" 关键字
Collection<String> tables = tableList(); // 解析表列表
Predicate pred = new Predicate(); // 默认创建一个空谓词
if (lex.matchKeyword("where")) { // 如果有 "where" 子句
lex.eatKeyword("where");
pred = predicate(); // 解析谓词
}
return new QueryData(fields, tables, pred); // 返回 QueryData 对象
}
// 解析选择列表 <SelectList> := <Field> [ , <SelectList> ]
private List<String> selectList() {
List<String> L = new ArrayList<String>();
L.add(field()); // 添加第一个字段
if (lex.matchDelim(',')) { // 如果有逗号
lex.eatDelim(',');
L.addAll(selectList()); // 递归解析并添加剩余字段
}
return L;
}
// 解析表列表 <TableList> := IdTok [ , <TableList> ]
private Collection<String> tableList() {
Collection<String> L = new ArrayList<String>();
L.add(lex.eatId()); // 添加第一个表名
if (lex.matchDelim(',')) { // 如果有逗号
lex.eatDelim(',');
L.addAll(tableList()); // 递归解析并添加剩余表名
}
return L;
}
// --- 解析各种更新命令的方法 ---
// 实现 <UpdateCmd> := <Insert> | <Delete> | <Modify> | <Create>
public Object updateCmd() {
if (lex.matchKeyword("insert")) {
return insert(); // 解析插入语句
} else if (lex.matchKeyword("delete")) {
return delete(); // 解析删除语句
} else if (lex.matchKeyword("update")) {
return modify(); // 解析修改语句
} else {
return create(); // 解析创建语句 (表、视图、索引)
}
}
// 实现 <Create> := <CreateTable> | <CreateView> | <CreateIndex>
private Object create() {
lex.eatKeyword("create");
if (lex.matchKeyword("table")) {
return createTable(); // 解析创建表语句
} else if (lex.matchKeyword("view")) {
return createView(); // 解析创建视图语句
} else {
return createIndex(); // 解析创建索引语句
}
}
// --- 解析删除命令的方法 ---
// 实现 <Delete> := DELETE FROM IdTok [ WHERE <Predicate> ]
public DeleteData delete() {
lex.eatKeyword("delete");
lex.eatKeyword("from");
String tblname = lex.eatId(); // 消费并获取表名
Predicate pred = new Predicate(); // 默认创建一个空谓词
if (lex.matchKeyword("where")) { // 如果有 "where" 子句
lex.eatKeyword("where");
pred = predicate(); // 解析谓词
}
return new DeleteData(tblname, pred); // 返回 DeleteData 对象
}
// --- 解析插入命令的方法 ---
// 实现 <Insert> := INSERT INTO IdTok ( <FieldList> ) VALUES ( <ConstList> )
public InsertData insert() {
lex.eatKeyword("insert");
lex.eatKeyword("into");
String tblname = lex.eatId(); // 消费并获取表名
lex.eatDelim('(');
List<String> flds = fieldList(); // 解析字段列表
lex.eatDelim(')');
lex.eatKeyword("values");
lex.eatDelim('(');
List<Constant> vals = constList(); // 解析常量列表
lex.eatDelim(')');
return new InsertData(tblname, flds, vals); // 返回 InsertData 对象
}
// 解析字段列表 <FieldList> := <Field> [ , <FieldList> ]
private List<String> fieldList() {
List<String> L = new ArrayList<String>();
L.add(field()); // 添加第一个字段
if (lex.matchDelim(',')) {
lex.eatDelim(',');
L.addAll(fieldList()); // 递归解析并添加剩余字段
}
return L;
}
// 解析常量列表 <ConstList> := <Constant> [ , <ConstList> ]
private List<Constant> constList() {
List<Constant> L = new ArrayList<Constant>();
L.add(constant()); // 添加第一个常量
if (lex.matchDelim(',')) {
lex.eatDelim(',');
L.addAll(constList()); // 递归解析并添加剩余常量
}
return L;
}
// --- 解析修改命令的方法 ---
// 实现 <Modify> := UPDATE IdTok SET <Field> = <Expression> [ WHERE <Predicate> ]
public ModifyData modify() {
lex.eatKeyword("update");
String tblname = lex.eatId(); // 消费并获取表名
lex.eatKeyword("set");
String fldname = field(); // 消费并获取要修改的字段名
lex.eatDelim('=');
Expression newval = expression(); // 解析新值表达式
Predicate pred = new Predicate(); // 默认创建一个空谓词
if (lex.matchKeyword("where")) { // 如果有 "where" 子句
lex.eatKeyword("where");
pred = predicate(); // 解析谓词
}
return new ModifyData(tblname, fldname, newval, pred); // 返回 ModifyData 对象
}
// --- 解析创建表命令的方法 ---
// 实现 <CreateTable> := CREATE TABLE IdTok ( <FieldDefs> )
public CreateTableData createTable() {
lex.eatKeyword("table");
String tblname = lex.eatId(); // 消费并获取表名
lex.eatDelim('(');
Schema sch = fieldDefs(); // 解析字段定义列表
lex.eatDelim(')');
return new CreateTableData(tblname, sch); // 返回 CreateTableData 对象
}
// 解析字段定义列表 <FieldDefs> := <FieldDef> [ , <FieldDefs> ]
private Schema fieldDefs() {
Schema schema = fieldDef(); // 解析第一个字段定义
if (lex.matchDelim(',')) {
lex.eatDelim(',');
Schema schema2 = fieldDefs(); // 递归解析剩余字段定义
schema.addAll(schema2); // 将所有字段定义合并到同一个 Schema
}
return schema;
}
// 解析单个字段定义 <FieldDef> := IdTok <TypeDef>
private Schema fieldDef() {
String fldname = field(); // 获取字段名
return fieldType(fldname); // 解析字段类型并返回包含该字段的 Schema
}
// 解析字段类型 <TypeDef> := INT | VARCHAR ( IntTok )
private Schema fieldType(String fldname) {
Schema schema = new Schema();
if (lex.matchKeyword("int")) {
lex.eatKeyword("int");
schema.addIntField(fldname); // 添加整数类型字段
} else {
lex.eatKeyword("varchar");
lex.eatDelim('(');
int strLen = lex.eatIntConstant(); // 获取 VARCHAR 长度
lex.eatDelim(')');
schema.addStringField(fldname, strLen); // 添加字符串类型字段
}
return schema;
}
// --- 解析创建视图命令的方法 ---
// 实现 <CreateView> := CREATE VIEW IdTok AS <Query>
public CreateViewData createView() {
lex.eatKeyword("view");
String viewname = lex.eatId(); // 消费并获取视图名
lex.eatKeyword("as");
QueryData qd = query(); // 解析底层查询
return new CreateViewData(viewname, qd); // 返回 CreateViewData 对象
}
// --- 解析创建索引命令的方法 ---
// 实现 <CreateIndex> := CREATE INDEX IdTok ON IdTok ( <Field> )
public CreateIndexData createIndex() {
lex.eatKeyword("index");
String idxname = lex.eatId(); // 消费并获取索引名
lex.eatKeyword("on");
String tblname = lex.eatId(); // 消费并获取表名
lex.eatDelim('(');
String fldname = field(); // 消费并获取索引字段名
lex.eatDelim(')');
return new CreateIndexData(idxname, tblname, fldname); // 返回 CreateIndexData 对象
}
}
图 9.10 SimpleDB QueryData 类的代码 (The code for the SimpleDB class QueryData)
import simpledb.query.Predicate; // 假设包含 Predicate 类
import java.util.*;
public class QueryData {
private List<String> fields; // 选择列表中的字段名
private Collection<String> tables; // FROM 子句中的表名
private Predicate pred; // WHERE 子句中的谓词
// 构造函数
public QueryData(List<String> fields, Collection<String> tables, Predicate pred) {
this.fields = fields;
this.tables = tables;
this.pred = pred;
}
// 返回字段列表
public List<String> fields() {
return fields;
}
// 返回表集合
public Collection<String> tables() {
return tables;
}
// 返回谓词
public Predicate pred() {
return pred;
}
// 重写 toString 方法,用于重新创建查询字符串
public String toString() {
String result = "select ";
for (String fldname : fields) {
result += fldname + ", ";
}
result = result.substring(0, result.length() - 2); // 移除末尾的逗号和空格
result += " from ";
for (String tblname : tables) {
result += tblname + ", ";
}
result = result.substring(0, result.length() - 2); // 移除末尾的逗号和空格
String predstring = pred.toString();
if (!predstring.equals("")) { // 如果谓词不为空
result += " where " + predstring;
}
return result;
}
}
9.6.3 解析更新语句 (Parsing Updates)
解析器方法 updateCmd 实现了句法范畴 <UpdateCmd>,它表示各种 SQL 更新语句的集合。在 JDBC 方法 executeUpdate 执行期间,会调用此方法来确定命令所表示的更新类型。该方法利用字符串的初始标记来识别命令,然后分派给特定命令的解析器方法。每个更新方法都有不同的返回类型,因为每个方法从其命令字符串中提取的信息不同;因此,updateCmd 方法返回一个 Object 类型的值。
9.6.4 解析插入语句 (Parsing Insertions)
解析器方法 insert 实现了句法范畴 <Insert>。此方法提取三个项:表名 (table name)、字段列表 (field list) 和值列表 (value list)。图 9.11 所示的 InsertData 类保存这些值并使其可通过访问器方法获取。
图 9.11 SimpleDB InsertData 类的代码 (The code for the SimpleDB class InsertData)
import java.util.List;
import simpledb.query.Constant; // 假设 Constant 类在 simpledb.query 包中
public class InsertData {
private String tblname; // 表名
private List<String> flds; // 字段列表
private List<Constant> vals; // 值列表
// 构造函数
public InsertData(String tblname, List<String> flds, List<Constant> vals) {
this.tblname = tblname;
this.flds = flds;
this.vals = vals;
}
// 获取表名
public String tableName() {
return tblname;
}
// 获取字段列表
public List<String> fields() {
return flds;
}
// 获取值列表
public List<Constant> vals() {
return vals;
}
}
9.6.5 解析删除语句 (Parsing Deletions)
删除语句由方法 delete 处理。该方法返回一个 DeleteData 类的对象;参见图 9.12。该类构造函数存储了指定删除语句中的表名 (table name) 和谓词 (predicate),并提供了 tableName 和 pred 方法来访问它们。
图 9.12 SimpleDB DeleteData 类的代码 (The code for the SimpleDB class DeleteData)
import simpledb.query.Predicate; // 假设 Predicate 类在 simpledb.query 包中
public class DeleteData {
private String tblname; // 表名
private Predicate pred; // 谓词
// 构造函数
public DeleteData(String tblname, Predicate pred) {
this.tblname = tblname;
this.pred = pred;
}
// 获取表名
public String tableName() {
return tblname;
}
// 获取谓词
public Predicate pred() {
return pred;
}
}
9.6.6 解析修改语句 (Parsing Modifications)
修改语句由方法 modify 处理。该方法返回一个 ModifyData 类的对象,如图 9.13 所示。这个类与 DeleteData 类非常相似。区别在于这个类还保存了赋值信息 (assignment information):赋值左侧的字段名 (fieldname) 和赋值右侧的表达式 (expression)。附加的方法 targetField 和 newValue 返回这些信息。
图 9.13 SimpleDB ModifyData 类的代码 (The code for the SimpleDB class ModifyData)
import simpledb.query.Expression; // 假设 Expression 类在 simpledb.query 包中
import simpledb.query.Predicate; // 假设 Predicate 类在 simpledb.query 包中
public class ModifyData {
private String tblname; // 表名
private String fldname; // 目标字段名 (被修改的字段)
private Expression newval; // 新值表达式
private Predicate pred; // 谓词
// 构造函数
public ModifyData(String tblname, String fldname, Expression newval, Predicate pred) {
this.tblname = tblname;
this.fldname = fldname;
this.newval = newval;
this.pred = pred;
}
// 获取表名
public String tableName() {
return tblname;
}
// 获取目标字段名
public String targetField() {
return fldname;
}
// 获取新值表达式
public Expression newValue() {
return newval;
}
// 获取谓词
public Predicate pred() {
return pred;
}
}
9.6.7 解析表、视图和索引创建语句 (Parsing Table, View, and Index Creation)
句法范畴 <Create> 指定了 SimpleDB 支持的三种 SQL 创建语句。表创建语句由句法范畴 <CreateTable> 及其方法 createTable 处理。fieldDef 和 fieldType 方法提取一个字段的信息并将其保存在自己的 Schema 对象中。fieldDefs 方法随后将此模式添加到表的模式中。表名和模式作为 CreateTableData 对象返回,其代码如 图 9.14 所示。
图 9.14 SimpleDB CreateTableData 类的代码 (The code for the SimpleDB class CreateTableData)
import simpledb.record.Schema; // 假设 Schema 类在 simpledb.record 包中
public class CreateTableData {
private String tblname; // 表名
private Schema sch; // 表的模式 (schema)
// 构造函数
public CreateTableData(String tblname, Schema sch) {
this.tblname = tblname;
this.sch = sch;
}
// 获取表名
public String tableName() {
return tblname;
}
// 获取新表的模式
public Schema newSchema() {
return sch;
}
}
视图创建语句由方法 createView 处理。该方法提取视图的名称 (name) 和定义 (definition),并将其作为 CreateViewData 类型的对象返回;参见图 9.15。视图定义 (view definition) 的处理方式有些特殊。它需要被解析为 <Query>,以便检测格式错误的视图定义。然而,元数据管理器不希望保存定义的解析表示;它需要实际的查询字符串。因此,CreateViewData 构造函数通过对返回的 QueryData 对象调用 toString 来重新创建视图定义。实际上,toString 方法“反解析 (unparses)”了查询。
图 9.15 SimpleDB CreateViewData 类的代码 (The code for the SimpleDB class CreateViewData)
import simpledb.parse.QueryData; // 假设 QueryData 类在 simpledb.parse 包中
public class CreateViewData {
private String viewname; // 视图名
private QueryData qrydata; // 视图底层查询的解析数据
// 构造函数
public CreateViewData(String viewname, QueryData qrydata) {
this.viewname = viewname;
this.qrydata = qrydata;
}
// 获取视图名
public String viewName() {
return viewname;
}
// 获取视图定义字符串 (通过 QueryData 的 toString 方法反解析得到)
public String viewDef() {
return qrydata.toString();
}
}
索引 (Index) 是数据库系统用于提高查询效率的数据结构;索引是第 12 章的主题。createIndex 解析器方法提取索引名 (index name)、表名 (table name) 和字段名 (field name),并将它们保存在 CreateIndexData 对象中;参见图 9.16。
图 9.16 SimpleDB CreateIndexData 类的代码 (The code for the SimpleDB class CreateIndexData)
public class CreateIndexData {
private String idxname, tblname, fldname; // 索引名, 表名, 字段名
// 构造函数
public CreateIndexData(String idxname, String tblname, String fldname) {
this.idxname = idxname;
this.tblname = tblname;
this.fldname = fldname;
}
// 获取索引名
public String indexName() {
return idxname;
}
// 获取表名
public String tableName() {
return tblname;
}
// 获取字段名
public String fieldName() {
return fldname;
}
}
9.7 章总结 (Chapter Summary)
-
语言的语法是一组规则,描述了可能构成有意义语句的字符串。
-
解析器负责确保其输入字符串在语法上是正确的。
-
词法分析器是解析器中负责将输入字符串分解成一系列标记的部分。
-
每个标记都具有类型和值
。SimpleDB 词法分析器支持五种标记类型:
- 单字符分隔符,例如逗号
,
- 单字符分隔符,例如逗号
-
整数常量,例如
123- 字符串常量,例如
'joe'
- 字符串常量,例如
-
关键字,例如
select、from和where- 标识符,例如
STUDENT、x和glop34a
- 标识符,例如
-
每种标记类型都有两种方法:查询当前标记信息的方法,以及告诉词法分析器“消费”当前标记(返回其值并移动到下一个标记)的方法。
-
语法
是一组规则,描述了标记如何合法地组合。
- 语法规则的左侧指定其句法范畴。句法范畴表示语言中的特定概念。
- 语法规则的右侧指定该范畴的内容,即满足规则的字符串集合。
-
解析树将其句法范畴作为其内部节点,将标记作为其叶节点。范畴节点的子节点对应于语法规则的应用。一个字符串属于某个句法范畴,当且仅当它有一个以该范畴为根的解析树。
-
解析算法从语法合法的字符串构造解析树。解析算法的复杂性通常与其能支持的语法的复杂性成正比。一种简单的解析算法被称为递归下降。
-
递归下降解析器为每个语法规则都有一个方法。每个方法调用对应于规则右侧项的方法。
-
递归下降解析器中的每个方法都提取它读取的标记的值并返回它们。SQL 解析器应该从 SQL 语句中提取诸如表名、字段名、谓词和常量等信息。提取的内容取决于 SQL 语句的类型:
- 对于查询:一个字段名集合(来自
select子句)、一个表名集合(来自from子句)和一个谓词(来自where子句)。 - 对于插入:一个表名、一个字段名列表和一个值列表。
- 对于删除:一个表名和一个谓词。
- 对于修改:一个表名、要修改的字段名、一个表示新字段值的表达式和一个谓词。
- 对于表创建:一个表名及其模式。
- 对于视图创建:一个表名及其定义。
- 对于索引创建:一个索引名、一个表名和被索引字段的名称。
- 对于查询:一个字段名集合(来自
9.8 建议阅读 (Suggested Reading)
词法分析和解析领域受到了极大的关注,追溯到 60 多年前。Scott (2000) 的书对当前使用的各种算法提供了很好的介绍。网上有许多 SQL 解析器可供使用,例如 Zql (zql.sourceforge.net)。SQL 语法可以在 Date 和 Darwen (2004) 的附录中找到。SQL-92 标准(描述了 SQL 及其语法)的副本可在 URL 获取。如果你从未看过标准文档,为了体验一下,你应该去看看。
- Date, C., & Darwen, H. (2004). SQL 标准指南 (A guide to the SQL standard) (第 4 版). Boston, MA: Addison Wesley.
- Scott, M. (2000). 编程语言实用指南 (Programming language pragmatics). San Francisco, CA: Morgan Kaufman.
9.9 练习 (Exercises)
概念问题 (Conceptual Problems)
9.1. 为以下 SQL 语句绘制解析树。
(a) select a from x where b = 3
(b) select a, b from x,y,z
(c) delete from x where a = b and c = 0
(d) update x set a = b where c = 3
(e) insert into x (a,b,c) values (3, 'glop', 4)
(f) create table x ( a varchar(3), b int, c varchar(2))
9.2. 对于以下每个字符串,说明在解析时会在哪里以及为什么会生成异常。然后从 JDBC 客户端执行每个查询,看看会发生什么。
(a) select from x
(b) select x x from x
(c) select x from y z
(d) select a from where b=3
(e) select a from y where b -=3
(f) select a from y where
9.3. 解析器方法 create 不符合图 9.7 的 SQL 语法。
(a) 解释为什么<Create> 的语法规则对于递归下降解析来说过于模糊。
(b) 修改语法,使其与 create 方法的实际工作方式相对应。
编程问题 (Programming Problems)
9.4. 修改每个对应于递归规则的解析器方法,使其使用 while 循环而不是递归。
9.5. 修改 PredParser 类(来自图 9.8),以打印方法调用序列产生的解析树。
9.6. 练习 8.8 要求你修改表达式以处理算术运算。
(a) 类似地修改 SQL 语法。
(b) 修改 SimpleDB 解析器以实现语法更改。
(c) 编写一个 JDBC 客户端来测试服务器。例如,编写一个程序来执行一个 SQL 查询,将所有主修 30 的学生的毕业年份增加。
9.7. 练习 8.9 要求你修改项。
(a) 类似地修改 SQL 语法。
(b) 修改 SimpleDB 解析器以实现语法更改。
(c) 编写一个 JDBC 客户端来测试服务器。例如,编写一个程序来执行一个 SQL 查询,检索所有 2010 年之前毕业的学生的姓名。
9.8. 练习 8.10 要求你修改谓词。
(a) 类似地修改 SQL 语法。
(b) 修改 SimpleDB 解析器以实现语法更改。
(c) 编写一个 JDBC 客户端来测试服务器。例如,编写一个程序来执行一个 SQL 查询,检索所有主修 10 或 20 的学生的姓名。
9.9. SimpleDB 也不允许在谓词中使用括号。
(a) 适当地修改 SQL 语法(无论是否已完成练习 9.8)。
(b) 修改 SimpleDB 解析器以实现语法更改。
(c) 编写一个 JDBC 客户端来测试你的更改。
9.10. 连接谓词可以在标准 SQL 中通过 from 子句中的 JOIN 关键字指定。例如,以下两个查询是等价的:
select SName, DName from STUDENT, DEPT where MajorId = Did and GradYear = 2020
select SName, DName from STUDENT join DEPT on MajorId = Did where GradYear = 2020
(a) 修改 SQL 词法分析器以包含关键字 “join” 和 “on”。
(b) 修改 SQL 语法以处理显式连接。
(c) 修改 SimpleDB 解析器以实现你的语法更改。将连接谓词添加到从 where 子句获取的谓词中。
(d) 编写一个 JDBC 程序来测试你的更改。
9.11. 在标准 SQL 中,表可以具有关联的范围变量。来自该表的字段引用以该范围变量为前缀。例如,以下查询等效于练习 9.10 中的任一查询:
select s.SName, d.DName from STUDENT s, DEPT d where s.MajorId = d.Did and s.GradYear = 2020
(a) 修改 SimpleDB 语法以允许此功能。
(b) 修改 SimpleDB 解析器以实现你的语法更改。你还必须修改解析器返回的信息。请注意,除非你也扩展了规划器,否则你将无法在 SimpleDB 服务器上测试你的更改;参见练习 10.13。
9.12. 关键字 AS 可以在标准 SQL 中用于使用计算值扩展输出表。例如:
select SName, GradYear-1 as JuniorYear from STUDENT
(a) 修改 SimpleDB 语法,允许在 select 子句中的任何字段之后添加可选的 AS 表达式。
(b) 修改 SimpleDB 词法分析器和解析器以实现你的语法更改。解析器应该如何使这些附加信息可用?请注意,除非你也扩展了规划器,否则你将无法在 SimpleDB 服务器上测试你的更改;参见练习 10.14。
9.13. 关键字 UNION 可以在标准 SQL 中用于组合两个查询的输出表。例如:
select SName from STUDENT where MajorId = 10 union select SName from STUDENT where MajorId = 20
(a) 修改 SimpleDB 语法,允许一个查询是另外两个查询的并集。
(b) 修改 SimpleDB 词法分析器和解析器以实现你的语法更改。请注意,除非你也扩展了规划器,否则你将无法在 SimpleDB 服务器上测试你的更改;参见练习 10.15。
9.14. 标准 SQL 支持 where 子句中的嵌套查询。例如:
select SName from STUDENT where MajorId in select Did from DEPT where DName = 'math'
(a) 修改 SimpleDB 语法,允许一个项的形式为“fieldname op query”,其中 op 是 “in” 或 “not in”。
(b) 修改 SimpleDB 词法分析器和解析器以实现你的语法更改。请注意,除非你也扩展了规划器,否则你将无法在 SimpleDB 服务器上测试你的更改;参见练习 10.16。
9.15. 在标准 SQL 中,select 子句可以使用字符 来表示表的所有字段。如果 SQL 支持范围变量(如练习 9.11),那么 同样可以以范围变量为前缀。
(a) 修改 SimpleDB 语法,允许 * 出现在查询中。
(b) 修改 SimpleDB 解析器以实现你的语法更改。请注意,除非你也扩展了规划器,否则你将无法在 SimpleDB 服务器上测试你的更改;参见练习 10.17。
9.16. 在标准 SQL 中,可以通过以下 insert 语句的变体将记录插入到表中:
insert into MATHSTUDENT(SId, SName) select SId, SName from STUDENT, DEPT where MajorId = DId and DName = 'math'
也就是说,select 语句返回的记录被插入到指定的表中。(上述语句假设 MATHSTUDENT 空表已创建。)
(a) 修改 SimpleDB SQL 语法以处理这种形式的插入。
(b) 修改 SimpleDB 解析器代码以实现你的语法。请注意,除非你也修改了规划器,否则你将无法运行 JDBC 查询;参见练习 10.18。
9.17. 练习 8.7 要求你创建新类型的常量。
(a) 修改 SimpleDB SQL 语法,允许在 create table 语句中使用这些类型。
(b) 你是否需要引入新的常量字面量?如果是,修改 <Constant> 句法范畴。
(c) 修改 SimpleDB 解析器代码以实现你的语法。
9.18. 练习 8.11 要求你实现空值。本练习要求你修改 SQL 以理解空值。
(a) 修改 SimpleDB 语法以接受关键字 null 作为常量。
(b) 修改 SimpleDB 解析器以实现第 (a) 部分的语法更改。
(c) 在标准 SQL 中,一个项可以是 GradYear is null 的形式,如果表达式 GradYear 为空值,则返回 true。关键字 is null 被视为具有一个参数的单个操作符。修改 SimpleDB 语法以具有此新操作符。
(d) 修改 SimpleDB 解析器和 Term 类以实现第 (c) 部分的语法更改。
(e) 编写一个 JDBC 程序来测试你的代码。你的程序可以将值设置为 null(或使用新插入记录的未赋值值),然后执行涉及 is null 的查询。请注意,除非你修改 SimpleDB 的 JDBC 实现,否则你的程序将无法打印空值;参见练习 11.6。
9.19. 开源软件包 javacc (参见 URL javacc.github.io/javacc) 根据语法规范构建解析器。使用 javacc 为 SimpleDB 语法创建一个解析器。然后用你的新解析器替换现有的解析器。
9.20. Parser 类包含一个对应于语法中每个句法范畴的方法。我们简化的 SQL 语法很小,因此该类易于管理。然而,一个功能齐全的语法将使该类显著增大。另一种实现策略是将每个句法范畴放在其自己的类中。类的构造函数将执行该范畴的解析。该类还将具有返回从解析标记中提取的值的方法。这种策略会创建大量类,每个类都相对较小。使用这种策略重写 SimpleDB 解析器。