第 10 章 规划 (Planning)
在查询处理的第一步中,解析器 (parser) 从 SQL 语句中提取相关数据。下一步是将这些数据转换为关系代数查询树。这一步称为规划 (planning)。本章探讨基本的规划过程。它探讨了规划器需要做什么来验证 SQL 语句是否具有语义意义,并介绍了两种基本计划构建算法 (plan-construction algorithms)。
一个 SQL 语句可以有许多等效的查询树,它们的成本往往差异巨大。一个希望在商业上可行的数据库系统必须有一个能够找到高效计划的规划算法。第 15 章将探讨创建最优计划的困难主题。
10.1 验证 (Verification)
规划器 (planner) 的首要职责是确定给定的 SQL 语句是否实际有意义。规划器需要验证语句的以下几点:
- 所提及的表和字段确实存在于目录 (catalog) 中。
- 所提及的字段没有歧义。
- 字段上的操作是类型正确 (type-correct) 的。
- 所有常量对于其字段来说都具有正确的大小 (size) 和类型 (type)。
执行此验证所需的所有信息都可以通过检查所提及表的模式 (schemas) 来找到。例如,模式的缺失表明所提及的表不存在。类似地,任何模式中字段的缺失表明该字段不存在,而它出现在多个模式中则表明可能存在歧义。
规划器还应该通过检查每个提及字段的类型和长度来确定谓词 (predicates)、修改赋值 (modification assignments) 和插入值 (inserted values) 的类型正确性。对于谓词,表达式中每个操作符的参数必须是兼容类型,每个项中的表达式也必须是兼容类型。修改语句将一个表达式赋值给一个字段;这两种类型必须兼容。对于插入语句,每个插入值的类型必须与其关联字段的类型兼容。
SimpleDB 规划器可以通过元数据管理器的 getLayout 方法获取必要的表模式。然而,规划器目前不执行任何显式验证。练习 10.4-10.8 要求您纠正这种情况。
10.2 评估查询树的成本 (The Cost of Evaluating a Query Tree)
规划器的第二个职责是为查询构建一个关系代数查询树 (relational algebra query tree)。一个复杂之处在于,一个 SQL 查询可以通过几种不同的查询树来实现,每个查询树都有自己的执行时间。规划器负责选择最有效的一个。
但是规划器如何计算查询树的效率呢?回想一下,查询运行时间最重要的贡献者是它访问的块数。因此,查询树的成本定义为完全迭代查询的扫描所需的块访问次数。
扫描的成本可以通过递归计算其子扫描的成本,然后应用基于扫描类型的成本公式来计算。图 10.1 给出了三个成本函数的公式。每个关系操作符都有自己的这些函数公式。成本函数是:
图 10.1 扫描的成本公式 (The cost formulas for scans)

- B(s) = 构建扫描 s 的输出所需的块访问次数。
- R(s) = 扫描 s 输出中的记录数。
- V(s,F) = 扫描 s 输出中不同 F 值的数量。
这些函数类似于统计管理器的 blocksAccessed、recordsOutput 和 distinctValues 方法。不同之处在于它们适用于扫描而不是表。
快速检查图 10.1 显示了三个成本函数之间的相互关系。给定一个扫描 s,规划器希望计算 B(s)。但如果 s 是两个表的乘积,那么 B(s) 的值取决于两个表的块数以及其左侧扫描中的记录数。如果左侧扫描涉及一个选择操作符,那么它的记录数取决于谓词中提及字段的不同值的数量。换句话说,规划器需要所有这三个函数。
以下小节将推导图 10.1 所示的成本函数,并举例说明如何使用它们来计算查询树的成本。
10.2.1 表扫描的成本 (The Cost of a Table Scan)
查询中的每个表扫描 (table scan) 都持有其当前的记录页,该记录页持有一个缓冲区,该缓冲区锁定一个页面。当该页面中的记录已被读取时,其缓冲区被解除锁定,并且文件中下一个块的记录页取代它的位置。因此,一次通过表扫描将精确地访问每个块一次,每次锁定一个缓冲区。因此,当 s 是一个表扫描时,B(s)、R(s) 和 V(s,F) 的值就是底层表中块数 (number of blocks)、记录数 (number of records) 和不同值的数量 (number of distinct values)。
10.2.2 选择扫描的成本 (The Cost of a Select Scan)
选择扫描 (select scan) s 有一个底层扫描;称之为 s1。每次调用 next 方法都会导致选择扫描对 s1.next 进行一次或多次调用;当对 s1.next 的调用返回 false 时,该方法将返回 false。每次调用 getInt、getString 或 getVal 都只是从 s1 请求字段值,不需要块访问。因此,遍历一个选择扫描所需的块访问次数与其底层扫描所需的块访问次数完全相同。也就是说:
B(s)=B(s1)
R(s) 和 V(s,F) 的计算取决于选择谓词。作为示例,我将分析选择谓词将字段与常量或另一个字段等同的常见情况。
常量选择 (Selection on a Constant)
假设谓词的形式为 A=c(其中 A 是某个字段)。假设 A 中的值是均匀分布 (equally distributed) 的,则将有 R(s1)/V(s1,A) 条记录匹配该谓词。也就是说:
R(s)=R(s1)/V(s1,A)
均匀分布的假设也意味着其他字段的值在输出中仍然是均匀分布的。也就是说:
V(s,A)=1
V(s,F)=V(s1,F) 对于所有其他字段 F
字段选择 (Selection on a Field)
现在假设谓词的形式为 A=B(其中 A 和 B 是字段)。在这种情况下,合理地假设字段 A 和 B 中的值以某种方式相关。特别是,假设如果 B 值多于 A 值(即 V(s1,A)<V(s1,B)),则每个 A 值都出现在 B 中的某个位置;如果 A 值多于 B 值,则情况相反。(这个假设在 A 和 B 具有键-外键关系 (key-foreign key relationship) 的典型情况下是确实如此的。)所以假设 B 值多于 A 值,并考虑 s1 中的任何一条记录。它的 A 值有 1/V(s1,B) 的机会与其 B 值匹配。类似地,如果 A 值多于 B 值,则它的 B 值有 1/V(s1,A) 的机会与其 A 值匹配。因此:
R(s)=R(s1)/max{V(s1,A),V(s1,B)}
均匀分布的假设也意味着每个 A 值与 B 值匹配的可能性均等。因此,我们有:
V(s,F)=min{V(s1,A),V(s1,B)} 对于 F=A 或 B
V(s,F)=V(s1,F) 对于所有除了 A 或 B 之外的字段 F
10.2.3 投影扫描的成本 (The Cost of a Project Scan)
与选择扫描一样,投影扫描 (project scan) 只有一个底层扫描(称为 s1),并且除了其底层扫描所需的块访问之外,不需要额外的块访问。此外,投影操作不改变记录数,也不改变任何记录的值。因此:
B(s)=B(s1)
R(s)=R(s1)
V(s,F)=V(s1,F) 对于所有字段 F
10.2.4 乘积扫描的成本 (The Cost of a Product Scan)
乘积扫描 (product scan) 有两个底层扫描,s1 和 s2。它的输出包含 s1 和 s2 中记录的所有组合。当遍历扫描时,底层扫描 s1 将被遍历一次,而底层扫描 s2 将为 s1 的每条记录遍历一次。以下公式随之而来:
B(s)=B(s1)+R(s1)⋅B(s2)
R(s)=R(s1)⋅R(s2)
V(s,F)=V(s1,F) 或 V(s2,F),取决于 F 属于哪个模式。
意识到 B(s) 的公式对于 s1 和 s2 是不对称的 (not symmetric) 是非常有趣和重要的。也就是说,语句
Scan s3 = new ProductScan(s1, s2);
可能导致与逻辑等价的语句
Scan s3 = new ProductScan(s2, s1);
不同数量的块访问。
它们能有多大不同?定义
RPB(s)=R(s)/B(s)
也就是说,RPB(s) 表示扫描 s 的“每块记录数”——每次块访问产生的平均输出记录数。上述公式可以重写如下:
B(s)=B(s1)+(RPB(s1)⋅B(s1)⋅B(s2))
主导项是 B(s)=B(s1)+R(s1)⋅B(s2)。如果你将此项与交换 s1 和 s2 后获得的项进行比较,你会发现当 s1 是 RPB 最低的底层扫描时,乘积扫描的成本通常是最低的。
例如,假设 s1 是 STUDENT 的表扫描,s2 是 DEPT 的表扫描。由于 STUDENT 记录比 DEPT 记录大,更多 DEPT 记录可以放入一个块中,这意味着 STUDENT 的 RPB 比 DEPT 小。上述分析表明,当 STUDENT 的扫描先进行时,磁盘访问次数最少。
10.2.5 一个具体示例 (A Concrete Example)
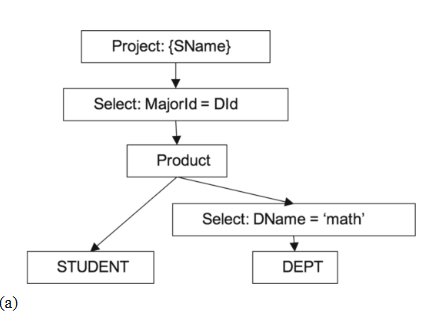
考虑一个查询,它返回主修数学的学生的姓名。图 10.2a 描绘了该查询的查询树 (query tree),图 10.2b 给出了相应扫描的 SimpleDB 代码。
图 10.2 查找主修数学的学生姓名。(a) 查询树,(b) 相应的 SimpleDB 扫描
// (b) 相应的 SimpleDB 扫描代码片段
SimpleDB db = new SimpleDB("studentdb");
Transaction tx = db.newTx();
MetadataMgr mdm = db.mdMgr();
// 获取 STUDENT 表的布局信息
Layout slayout = mdm.getLayout("student", tx);
// 获取 DEPT 表的布局信息
Layout dlayout = mdm.getLayout("dept", tx);
// s1: 对 STUDENT 表的表扫描
Scan s1 = new TableScan(tx, "student", slayout);
// s2: 对 DEPT 表的表扫描
Scan s2 = new TableScan(tx, "dept", dlayout);
// pred1: 谓词,例如 DName='math'
Predicate pred1 = new Predicate(. . .); // 例如:new Term(new Expression("dname"), new Expression(new Constant("math")))
// s3: 对 s2 (DEPT 表) 的选择扫描,过滤 DName='math'
Scan s3 = new SelectScan(s2, pred1);
// s4: s1 (STUDENT) 和 s3 (选择后的 DEPT) 的乘积扫描
Scan s4 = new ProductScan(s1, s3);
// pred2: 谓词,例如 majorid=did
Predicate pred2 = new Predicate(. . .); // 例如:new Term(new Expression("majorid"), new Expression("did"))
// s5: 对 s4 (乘积结果) 的选择扫描,过滤 majorid=did
Scan s5 = new SelectScan(s4, pred2);
// fields: 要投影的字段列表,例如 "sname"
List<String> fields = Arrays.asList("sname");
// s6: 对 s5 (选择后的乘积结果) 的投影扫描
Scan s6 = new ProjectScan(s5, fields);
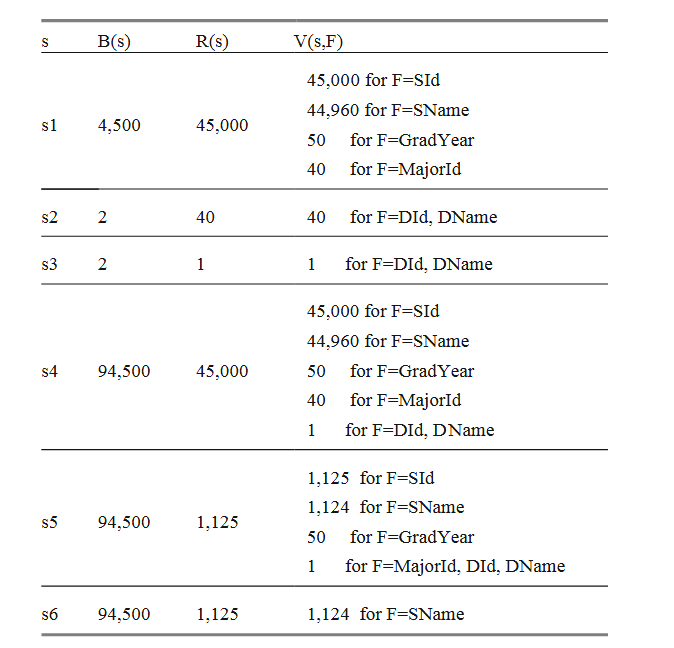
图 10.3 使用图 7.8 中的统计元数据 (statistical metadata) 计算了图 10.2b 中每个扫描的成本。s1 和 s2 的条目只是简单地复制了图 7.8 中 STUDENT 和 DEPT 的统计数据。s3 的条目表示对 DName 的选择返回 1 条记录,但需要搜索 DEPT 的两个块才能找到它。扫描 s4 返回 45,000 条 STUDENT 记录与 1 条选定记录的所有组合;输出为 45,000 条记录。然而,该操作需要 94,500 次块访问,因为必须找到唯一的数学系记录 45,000 次,并且每次都需要对 DEPT 进行 2 个块的扫描。(另外 4500 次块访问来自对 STUDENT 的单次扫描。)扫描 s5 中对 MajorId 的选择将输出减少到 1125 条记录(45,000 名学生 / 40 个系),但不会改变所需的块访问次数。当然,投影操作什么也不会改变。
图 10.3 查询树的成本 (Cost of the Query Tree)
数据库系统会重新计算数学系记录 45,000 次,并且代价高昂,这可能看起来很奇怪;然而,这就是管道式查询处理 (pipelined query processing) 的本质。(事实上,在这种情况下,第 13 章的非管道式实现会很有用。)
查看 STUDENT 和 s3 的 RPB 值,你会发现 RPB(STUDENT) = 10,而 RPB(s3) = 0.5。由于当 RPB 较小的扫描位于左侧时,乘积操作最快,因此更有效的策略是将 s4 定义如下:
s4 = new ProductScan(s3, STUDENT)
练习 10.3 要求你证明在这种情况下,操作仅需要 4502 次块访问。这种差异主要归因于现在只计算了一次选择操作。
10.3 计划 (Plans)
SimpleDB 中计算查询树成本的对象被称为计划 (plan)。计划实现了 Plan 接口,其代码如 图 10.4 所示。
该接口支持 blocksAccessed、recordsOutput 和 distinctValues 方法,这些方法用于计算查询的 B(s)、R(s) 和 V(s,F) 值。schema 方法返回输出表的模式。查询规划器可以使用此模式来验证类型正确性并寻找优化计划的方法。最后,每个计划都有 open 方法,它创建其对应的扫描。
计划和扫描在概念上是相似的,因为它们都表示一个查询树。区别在于,计划访问查询中表的元数据,而扫描访问它们的数据。当你提交一个 SQL 查询时,数据库规划器可能会为该查询创建多个计划,并使用它们的元数据来选择最有效的一个。然后,它使用该计划的 open 方法来创建所需的扫描。
计划的构建方式与扫描类似。每个关系代数操作符都有一个 Plan 类,外加用于处理存储表的 TablePlan 类。例如,图 10.5 的代码检索了主修数学的学生的姓名,与图 10.2 中的查询相同。唯一的区别是图 10.5 使用计划构建查询树,并将最终计划转换为扫描。
图 10.4 SimpleDB Plan 接口 (The SimpleDB Plan interface)
import simpledb.record.Schema; // 假设 Schema 类在 simpledb.record 包中
import simpledb.query.Scan; // 假设 Scan 接口在 simpledb.query 包中
public interface Plan {
// 创建并返回与此计划对应的 Scan 对象
public Scan open();
// 返回执行此计划所需的块访问次数 (B(s))
public int blocksAccessed();
// 返回此计划输出的记录数 (R(s))
public int recordsOutput();
// 返回此计划输出中指定字段的不同值的数量 (V(s, F))
public int distinctValues(String fldname);
// 返回此计划输出的表的模式
public Schema schema();
}
图 10.5 使用计划创建查询 (Using plans to create a query)
import simpledb.server.SimpleDB; // 假设 SimpleDB 类在 simpledb.server 包中
import simpledb.tx.Transaction; // 假设 Transaction 类在 simpledb.tx 包中
import simpledb.metadata.MetadataMgr; // 假设 MetadataMgr 类在 simpledb.metadata 包中
import simpledb.plan.*; // 假设 Plan 相关的类 (TablePlan, SelectPlan, ProductPlan, ProjectPlan) 在 simpledb.plan 包中
import simpledb.query.Predicate; // 假设 Predicate 类在 simpledb.query 包中
import simpledb.query.Scan; // 假设 Scan 接口在 simpledb.query 包中
import java.util.Arrays;
import java.util.List;
// 初始化 SimpleDB 数据库实例
SimpleDB db = new SimpleDB("studentdb");
// 获取元数据管理器
MetadataMgr mdm = db.mdMgr();
// 开启一个新事务
Transaction tx = db.newTx();
// p1: 创建 STUDENT 表的计划
Plan p1 = new TablePlan(tx, "student", mdm);
// p2: 创建 DEPT 表的计划
Plan p2 = new TablePlan(tx, "dept", mdm);
// pred1: 谓词,例如 DName='math' (具体实现需要根据 Predicate 类的构造函数)
Predicate pred1 = new Predicate(/* ... */); // 例如:new Term(new Expression("dname"), new Expression(new Constant("math")))
// p3: 对 p2 (DEPT 表) 的选择计划,过滤 DName='math'
Plan p3 = new SelectPlan(p2, pred1);
// p4: p1 (STUDENT) 和 p3 (选择后的 DEPT) 的乘积计划
Plan p4 = new ProductPlan(p1, p3);
// pred2: 谓词,例如 majorid=did (具体实现需要根据 Predicate 类的构造函数)
Predicate pred2 = new Predicate(/* ... */); // 例如:new Term(new Expression("majorid"), new Expression("did"))
// p5: 对 p4 (乘积结果) 的选择计划,过滤 majorid=did
Plan p5 = new SelectPlan(p4, pred2);
// fields: 要投影的字段列表,例如 "sname"
List<String> fields = Arrays.asList("sname");
// p6: 对 p5 (选择后的乘积结果) 的投影计划
Plan p6 = new ProjectPlan(p5, fields);
// 使用最终计划 p6 创建对应的 Scan 对象
Scan s = p6.open();
图 10.6、10.7、10.8、10.9 和 10.10 给出了 TablePlan、SelectPlan、ProjectPlan 和 ProductPlan 类的代码。TablePlan 类直接从元数据管理器获取其成本估算。其他类使用上一节的公式计算它们的估算值。
选择计划的成本估算比其他操作符更复杂,因为估算值取决于谓词。因此,谓词具有 reductionFactor 和 equatesWithConstant 方法供选择计划使用。reductionFactor 方法被 recordsAccessed 使用,以计算谓词减少输入表大小的程度。equatesWithConstant 方法被 distinctValues 使用,以确定谓词是否将指定字段与常量等同。
ProjectPlan 和 ProductPlan 的构造函数从其底层计划的模式创建它们的模式。ProjectPlan 模式是通过查找底层字段列表的每个字段并将该信息添加到新模式中来创建的。ProductPlan 模式是底层模式的并集。
这些计划类中每个 open 方法都很直接。通常,从计划构建扫描有两个步骤:首先,该方法递归地为每个底层计划构建一个扫描。其次,它将这些扫描传递给操作符的 Scan 构造函数。
图 10.6 SimpleDB TablePlan 类的代码 (The code for the SimpleDB class TablePlan)
import simpledb.query.Scan;
import simpledb.query.TableScan; // 假设 TableScan 类在 simpledb.query 包中
import simpledb.record.Layout; // 假设 Layout 类在 simpledb.record 包中
import simpledb.record.Schema; // 假设 Schema 类在 simpledb.record 包中
import simpledb.tx.Transaction; // 假设 Transaction 类在 simpledb.tx 包中
import simpledb.metadata.MetadataMgr; // 假设 MetadataMgr 类在 simpledb.metadata 包中
import simpledb.stats.StatInfo; // 假设 StatInfo 类在 simpledb.stats 包中
public class TablePlan implements Plan {
private Transaction tx;
private String tblname;
private Layout layout; // 表的布局
private StatInfo si; // 表的统计信息
// 构造函数
public TablePlan(Transaction tx, String tblname, MetadataMgr md) {
this.tx = tx;
this.tblname = tblname;
// 从元数据管理器获取表的布局
layout = md.getLayout(tblname, tx);
// 从元数据管理器获取表的统计信息
si = md.getStatInfo(tblname, layout, tx);
}
// 创建并返回一个 TableScan 对象
public Scan open() {
return new TableScan(tx, tblname, layout);
}
// 返回表访问的块数 (从统计信息获取)
public int blocksAccessed() {
return si.blocksAccessed();
}
// 返回表中的记录数 (从统计信息获取)
public int recordsOutput() {
return si.recordsOutput();
}
// 返回指定字段的不同值数量 (从统计信息获取)
public int distinctValues(String fldname) {
return si.distinctValues(fldname);
}
// 返回表的模式 (从布局获取)
public Schema schema() {
return layout.schema();
}
}
图 10.7 SimpleDB SelectPlan 类的代码 (The code for the SimpleDB class SelectPlan)
import simpledb.query.Predicate; // 假设 Predicate 类在 simpledb.query 包中
import simpledb.query.Scan; // 假设 Scan 接口在 simpledb.query 包中
import simpledb.query.SelectScan; // 假设 SelectScan 类在 simpledb.query 包中
import simpledb.record.Schema; // 假设 Schema 类在 simpledb.record 包中
public class SelectPlan implements Plan {
private Plan p; // 底层计划
private Predicate pred; // 选择谓词
// 构造函数
public SelectPlan(Plan p, Predicate pred) {
this.p = p;
this.pred = pred;
}
// 创建并返回一个 SelectScan 对象,底层扫描通过 p.open() 获取
public Scan open() {
Scan s = p.open();
return new SelectScan(s, pred);
}
// 返回块访问数 (与底层计划相同)
public int blocksAccessed() {
return p.blocksAccessed();
}
// 返回记录数 (底层计划记录数 / 谓词的归约因子)
public int recordsOutput() {
return p.recordsOutput() / pred.reductionFactor(p);
}
// 返回指定字段的不同值数量
public int distinctValues(String fldname) {
// 如果谓词将字段与常量等同,则不同值为 1
if (pred.equatesWithConstant(fldname) != null) {
return 1;
} else {
// 如果谓词将字段与另一个字段等同
String fldname2 = pred.equatesWithField(fldname);
if (fldname2 != null) {
// 不同值为两个字段不同值数量的最小值
return Math.min(p.distinctValues(fldname), p.distinctValues(fldname2));
} else {
// 否则,不同值数量与底层计划相同
return p.distinctValues(fldname);
}
}
}
// 返回模式 (与底层计划相同)
public Schema schema() {
return p.schema();
}
}
图 10.8 SimpleDB ProjectPlan 类的代码 (The code for the SimpleDB class ProjectPlan)
import simpledb.query.ProjectScan; // 假设 ProjectScan 类在 simpledb.query 包中
import simpledb.query.Scan; // 假设 Scan 接口在 simpledb.query 包中
import simpledb.record.Schema; // 假设 Schema 类在 simpledb.record 包中
import java.util.List;
public class ProjectPlan implements Plan {
private Plan p; // 底层计划
private Schema schema = new Schema(); // 投影后的模式
// 构造函数
public ProjectPlan(Plan p, List<String> fieldlist) {
this.p = p;
// 根据字段列表和底层计划的模式构建新的模式
for (String fldname : fieldlist) {
schema.add(fldname, p.schema());
}
}
// 创建并返回一个 ProjectScan 对象
public Scan open() {
Scan s = p.open();
return new ProjectScan(s, schema.fields()); // ProjectScan 需要的是字段名列表
}
// 返回块访问数 (与底层计划相同)
public int blocksAccessed() {
return p.blocksAccessed();
}
// 返回记录数 (与底层计划相同)
public int recordsOutput() {
return p.recordsOutput();
}
// 返回指定字段的不同值数量 (与底层计划相同)
public int distinctValues(String fldname) {
return p.distinctValues(fldname);
}
// 返回投影后的模式
public Schema schema() {
return schema;
}
}
10.4 查询计划 (Query Planning)
我们回顾一下,解析器将 SQL 查询字符串作为输入,并返回一个 QueryData 对象作为输出。本节将探讨如何从这个 QueryData 对象构建一个计划。
10.4.1 SimpleDB 查询规划算法 (The SimpleDB Query Planning Algorithm)
SimpleDB 支持一个简化的 SQL 子集,它不包含计算、排序、分组、嵌套和重命名等复杂操作。因此,其所有 SQL 查询都可以通过仅使用选择 (select)、投影 (project) 和乘积 (product) 这三个操作符的查询树来实现。创建此类计划的算法如 图 10.10 所示。
图 10.9 SimpleDB ProductPlan 类的代码 (The code for the SimpleDB class ProductPlan)
import simpledb.query.ProductScan;
import simpledb.query.Scan;
import simpledb.record.Schema;
public class ProductPlan implements Plan {
private Plan p1, p2; // 两个底层计划
private Schema schema = new Schema(); // 乘积后的模式
// 构造函数:初始化两个底层计划,并合并它们的模式
public ProductPlan(Plan p1, Plan p2) {
this.p1 = p1;
this.p2 = p2;
schema.addAll(p1.schema());
schema.addAll(p2.schema());
}
// open 方法:打开底层计划的扫描,然后返回一个 ProductScan
public Scan open() {
Scan s1 = p1.open();
Scan s2 = p2.open();
return new ProductScan(s1, s2);
}
// blocksAccessed 方法:计算乘积操作的块访问成本
public int blocksAccessed() {
return p1.blocksAccessed()
+ (p1.recordsOutput() * p2.blocksAccessed());
}
// recordsOutput 方法:计算乘积操作的记录输出数
public int recordsOutput() {
return p1.recordsOutput() * p2.recordsOutput();
}
// distinctValues 方法:返回指定字段的不同值数量(取决于字段属于哪个底层计划)
public int distinctValues(String fldname) {
if (p1.schema().hasField(fldname))
return p1.distinctValues(fldname);
else
return p2.distinctValues(fldname);
}
// schema 方法:返回乘积操作的模式
public Schema schema() {
return schema;
}
}
图 10.10 SimpleDB SQL 子集的基本查询规划算法 (The basic query planning algorithm for the SimpleDB subset of SQL)
- 为
from子句中的每个表T构建一个计划。 a) 如果T是一个存储表,那么该计划就是T的一个表计划。 b) 如果T是一个视图,那么该计划是递归调用此算法来处理T定义的结果。 - 按照给定顺序,对这些表计划进行乘积操作。
- 根据
where子句中的谓词进行选择操作。 - 根据
select子句中的字段进行投影操作。
作为此查询规划算法的一个示例,考虑图 10.11。图 (a) 给出了一个 SQL 查询,它检索获得“A”成绩的爱因斯坦教授的学生姓名。图 (b) 是该算法生成的查询树。
图 10.11 将基本查询规划算法应用于 SQL 查询 (Example of the Query Planning Algorithm)
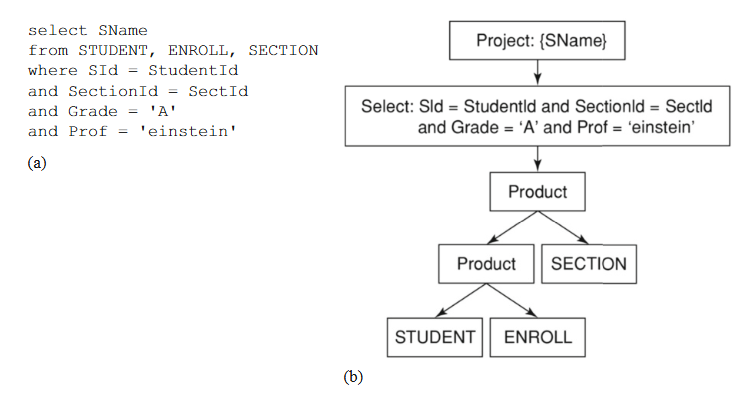
(a) SQL 查询 (SQL Query):
SELECT SName
FROM STUDENT, ENROLL, COURSE, SECTION
WHERE SId = StudId AND SectId = SectionId AND CourseId = CId AND Prof = 'Einstein' AND Grade = 'A'
图 10.12 说明了使用视图的等效查询的查询规划算法。图 (a) 给出了视图定义和查询,图 (b) 描绘了视图的查询树,图 (c) 描绘了整个查询的查询树。
图 10.12 在存在视图的情况下应用基本查询规划算法 .(a) SQL 查询,(b) 视图的树,(c) 整个查询的树
(a) 视图定义和查询 (View Definition and Query):
-- 视图定义
CREATE VIEW MathStudents AS
SELECT SName, MajorId, GradYear FROM STUDENT WHERE MajorId = 30;
-- 使用视图的查询
SELECT SName FROM MathStudents WHERE GradYear < 2025;
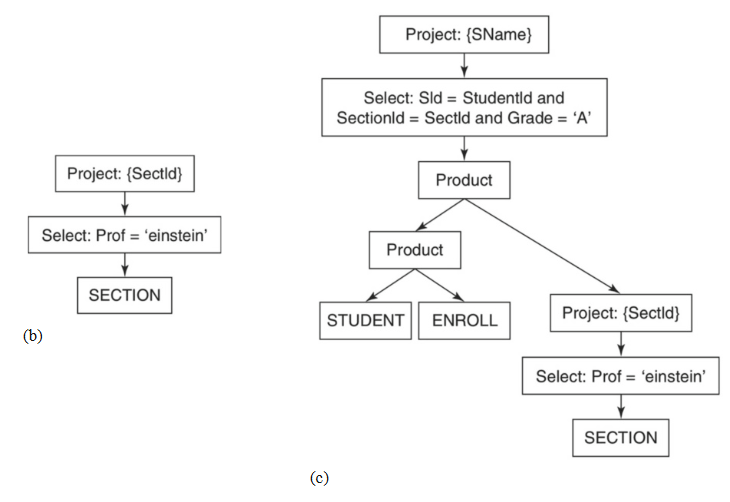
要了解这种查询规划算法的示例,请考虑图 10.11。图 (a) 给出了一个 SQL 查询,它检索获得爱因斯坦教授“A”成绩的学生的姓名。图 (b) 是该算法生成的查询树。
图 10.12 说明了使用视图的等效查询的查询规划算法。图 (a) 给出了视图定义和查询,图 (b) 描绘了视图的查询树,图 (c) 描绘了整个查询的树。
请注意,最终的树由两个表的乘积和视图树组成,然后是选择和投影。这个最终的树与图 10.11b 的树是等效的,但又有些不同。特别是,原始选择谓词的一部分已被“下推”到树的下方,并且存在一个中间投影。第 15 章的查询优化技术利用了这种等价性。
10.4.2 实现查询规划算法 (Implementing the Query Planning Algorithm)
SimpleDB 的 BasicQueryPlanner 类实现了基本的查询规划算法;其代码如 图 10.13 所示。代码中的四个步骤实现了该算法中对应的步骤。
图 10.13 SimpleDB BasicQueryPlanner 类的代码 (The code for the SimpleDB class BasicQueryPlanner)
import simpledb.tx.Transaction;
import simpledb.metadata.MetadataMgr;
import simpledb.parse.Parser;
import simpledb.parse.QueryData;
import java.util.ArrayList;
import java.util.List;
public class BasicQueryPlanner implements QueryPlanner { // 假设 QueryPlanner 是一个接口
private MetadataMgr mdm;
public BasicQueryPlanner(MetadataMgr mdm) {
this.mdm = mdm;
}
public Plan createPlan(QueryData data, Transaction tx) {
// 步骤 1: 为每个提及的表或视图创建计划。
List<Plan> plans = new ArrayList<Plan>();
for (String tblname : data.tables()) {
String viewdef = mdm.getViewDef(tblname, tx);
if (viewdef != null) { // 如果是视图,则递归规划视图
Parser parser = new Parser(viewdef);
QueryData viewdata = parser.query();
plans.add(createPlan(viewdata, tx));
} else { // 否则,创建表计划
plans.add(new TablePlan(tx, tblname, mdm));
}
}
// 步骤 2: 创建所有表计划的乘积
Plan p = plans.remove(0); // 取出第一个计划作为初始计划
for (Plan nextplan : plans) // 将剩余的计划逐个与当前计划进行乘积操作
p = new ProductPlan(p, nextplan);
// 步骤 3: 添加一个谓词的选择计划
p = new SelectPlan(p, data.pred());
// 步骤 4: 对字段名称进行投影
return new ProjectPlan(p, data.fields());
}
}
基本的查询规划算法是僵化且幼稚的。它按照 QueryData.tables 方法返回的顺序生成乘积计划。请注意,这个顺序是完全任意的——任何其他表的顺序都会产生等效的扫描。因此,该算法的性能将是不稳定的(而且通常很差),因为它没有使用计划元数据来帮助确定乘积计划的顺序。
图 10.14 展示了规划算法的一个小改进。它仍然以相同的顺序考虑表,但现在为每个表创建两个乘积计划——一个作为乘积的左侧,一个作为右侧——并保留成本最小的计划。
图 10.14 SimpleDB BetterQueryPlanner 类的代码 (The code for the SimpleDB class BetterQueryPlanner)
public class BetterQueryPlanner implements QueryPlanner {
// ... 其他方法和字段(与 BasicQueryPlanner 相似)
public Plan createPlan(QueryData data, Transaction tx) {
// ... (步骤 1 与 BasicQueryPlanner 相同)
List<Plan> plans = new ArrayList<Plan>();
for (String tblname : data.tables()) {
String viewdef = mdm.getViewDef(tblname, tx);
if (viewdef != null) {
Parser parser = new Parser(viewdef);
QueryData viewdata = parser.query();
plans.add(createPlan(viewdata, tx));
} else {
plans.add(new TablePlan(tx, tblname, mdm));
}
}
// 步骤 2: 创建所有表计划的乘积
// 在每一步,选择成本最小的计划
Plan p = plans.remove(0); // 初始化为第一个计划
for (Plan nextplan : plans) {
// 尝试两种乘积顺序:(nextplan * p) 和 (p * nextplan)
Plan p1 = new ProductPlan(nextplan, p);
Plan p2 = new ProductPlan(p, nextplan);
// 选择块访问次数较少的那个
p = (p1.blocksAccessed() < p2.blocksAccessed() ? p1 : p2);
}
// ... (步骤 3 和 4 与 BasicQueryPlanner 相同)
p = new SelectPlan(p, data.pred());
return new ProjectPlan(p, data.fields());
}
}
这个算法比基本的规划算法更好,但它仍然过于依赖查询中表的顺序。商业数据库系统中的规划算法要复杂得多。它们不仅分析许多等效计划的成本;它们还在特殊情况下实现可以应用的附加关系操作。它们的目标是选择最有效的计划(从而比竞争对手更具吸引力)。这些技术是第 12、13、14 和 15 章的主题。