第 8 章 查询处理 (Query Processing)
接下来的三章将探讨数据库引擎如何执行 SQL 查询。问题在于 SQL 查询指定了要返回什么数据,但没有指定如何获取这些数据。解决方案是让引擎实现一组数据检索操作符,称为关系代数 (relational algebra)。引擎可以将 SQL 查询翻译成关系代数查询,然后执行。本章将介绍关系代数查询及其实现。接下来的两章将探讨 SQL 到关系代数的翻译。
8.1 关系代数 (Relational Algebra)
关系代数由一组操作符组成。每个操作符执行一个专门的任务,接受一个或多个表作为输入,并产生一个输出表。可以通过以各种方式组合这些操作符来构建复杂的查询。
SimpleDB 版本的 SQL 可以使用以下三个操作符来实现:
- 选择 (select):其输出表与输入表具有相同的列,但删除了一些行。
- 投影 (project):其输出表与输入表具有相同的行,但删除了一些列。
- 乘积 (product):其输出表由其两个输入表的所有可能记录组合组成。
这些操作符将在以下小节中进行探讨。
8.1.1 选择 (Select)
选择 (select) 操作符接受两个参数:一个输入表和一个谓词。输出表由满足谓词的输入记录组成。选择查询总是返回一个与输入表具有相同模式但记录是其子集的表。
例如,查询 Q1 返回一个列出 2019 年毕业的学生的表。
Q1=select(STUDENT,GradYear=2019)
谓词可以是项的任何布尔组合,对应于 SQL 中的 WHERE 子句。例如,查询 Q2 查找那些 2019 年毕业且专业为 10 或 20 部门的学生。
Q2=select(STUDENT,GradYear=2019 and (MajorId=10 or MajorId=20))
一个查询的输出表可以作为另一个查询的输入。例如,查询 Q3 和 Q4 都等价于 Q2:
Q3=select(select(STUDENT,GradYear=2019),MajorId=10 or MajorId=20)
Q4=select(Q1,MajorId=10 or MajorId=20)
在 Q3 中,最外层查询的第一个参数是另一个查询,与 Q1 相同,它查找 2019 年毕业的学生。外层查询从这些记录中检索 10 或 20 部门的学生。查询 Q4 类似,只是它使用 Q1 的名称代替了其定义。
关系代数查询可以用图形表示,作为查询树 (query tree)。查询树包含查询中提到的每个表和操作符的节点。表节点是树的叶子,操作符节点是非叶子。操作符节点为其每个输入表都有一个子节点。例如,Q3 的查询树如 图 8.1 所示。
图 8.1 Q3 的查询树 (A query tree for Q3)
select MajorId=10 or MajorId=20
|
select GradYear=2019
|
STUDENT
8.1.2 投影 (Project)
投影 (project) 操作符接受两个参数:一个输入表和一组字段名。输出表与输入表具有相同的记录,但其模式只包含那些指定的字段。例如,查询 Q5 返回所有学生的姓名和毕业年份:
Q5=project(STUDENT,{SName,GradYear})
一个查询可以由投影和选择操作符组成。查询 Q6 返回一个列出所有主修 10 部门的学生的姓名的表:
Q6=project(select(STUDENT,MajorId=10),{SName})
Q6 的查询树如 图 8.2 所示。
图 8.2 Q6 的查询树 (A query tree for Q6)
project {SName}
|
select MajorId=10
|
STUDENT
投影查询的输出表可能包含重复记录。例如,如果有三个名叫“pat”且专业为 10 的学生,则 Q6 的输出将包含“pat”三次。
并非所有操作符的组合都有意义。例如,考虑通过反转 Q6 得到的查询:
Q7=select(project(STUDENT,{SName}),MajorId=10) // 不合法!
这个查询没有意义,因为内部查询的输出表不包含可以进行选择的 MajorId 字段。
8.1.3 乘积 (Product)
选择和投影操作符作用于单个表。乘积 (product) 操作符使得组合和比较来自多个表的信息成为可能。该操作符接受两个输入表作为参数。其输出表由输入表的所有记录组合组成,其模式由输入模式中字段的并集组成。输入表必须具有不相交的字段名,以便输出表不会有两个同名字段。
图 8.3 查询 Q8 的输出 (The output of query Q8)
这是 STUDENT 表和 DEPT 表的乘积结果示例。
假设 STUDENT 表有字段 (SId, SName, MajorId, GradYear),DEPT 表有字段 (DId, DName)。
Q8 的输出将是:
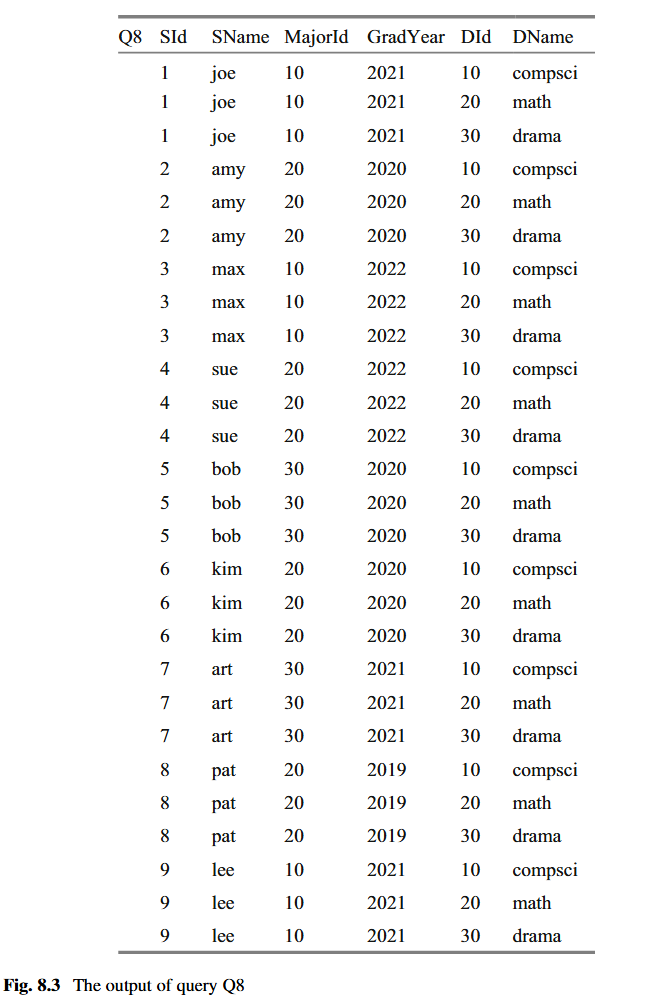
查询 Q8 返回 STUDENT 和 DEPT 表的乘积:
Q8=product(STUDENT,DEPT)
图 1.1 的大学数据库中 STUDENT 表有 9 条记录,DEPT 表有 3 条记录。图 8.3 描绘了给定这些输入表时 Q8 的输出。输出表包含 27 条记录,每条记录都是学生记录与部门记录的每个配对。通常,如果 STUDENT 表有 N 条记录,DEPT 表有 M 条记录,那么输出表将包含 N×M 条记录(顺便说一句,这就是为什么该操作符被称为“乘积”的原因)。
查询 Q8 并没有特别的意义,因为它没有考虑到每个学生的专业。这种意义可以通过选择谓词来表达,如查询 Q9 和 图 8.4 所示: 图 8.4 Q9 的查询树 (The query tree for Q9)
select MajorId=DId
|
product DEPT
|
STUDENT
Q9=select(product(STUDENT,DEPT),MajorId=DId)
这个查询的输出表只包含满足谓词的 STUDENT 和 DEPT 记录的组合。因此,在 27 种可能的组合中,只有那些学生的专业 ID 与部门 ID 相同的组合会保留下来——换句话说,结果表将由学生及其所属专业的部门组成。输出表现在有 9 条记录,而不是 27 条。
8.2 扫描 (Scans)
扫描 (Scan) 是一个对象,它表示关系代数查询的输出。SimpleDB 中的扫描实现了 Scan 接口;参见 图 8.5。Scan 方法是 TableScan 方法的一个子集,并且它们具有相同的行为。这种对应关系不足为奇——查询的输出是一个表,因此查询和表的访问方式相同是很自然的。
例如,考虑 图 8.6 中的 printNameAndGradYear 方法。
图 8.5 SimpleDB Scan 接口 (The SimpleDB Scan interface)
public interface Scan {
// 将扫描器定位到第一个记录之前
public void beforeFirst();
// 移动到下一条记录,如果存在则返回 true
public boolean next();
// 获取指定字段的整数值
public int getInt(String fldname);
// 获取指定字段的字符串值
public String getString(String fldname);
// 获取指定字段的 Constant 值(通用类型)
public Constant getVal(String fldname);
// 检查扫描结果是否包含指定字段
public boolean hasField(String fldname);
// 关闭扫描器,释放资源
public void close();
}
图 8.6 打印扫描记录的姓名和毕业年份 (Printing the name and graduation year of a scan’s records)
public static void printNameAndGradyear(Scan s) {
s.beforeFirst(); // 将扫描器定位到第一个记录之前
while (s.next()) { // 遍历扫描器的所有记录
String sname = s.getString("sname"); // 获取 sname 字段的值
int gradyr = s.getInt("gradyear"); // 获取 gradyear 字段的值
System.out.println(sname + "\t" + gradyr); // 打印姓名和毕业年份
}
s.close(); // 关闭扫描器
}
此示例的重点是,该方法不知道扫描代表什么查询(或表)。它可能代表 STUDENT 表,或者可能是一个选择特定专业学生或与爱因斯坦教授一起上课的学生的查询。唯一的要求是扫描的输出表包含学生姓名和毕业年份。
一个 Scan 对象对应于查询树中的一个节点。SimpleDB 为每个关系操作符包含一个 Scan 类。这些类的对象构成了查询树的内部节点,而 TableScan 对象表示树的叶子。图 8.7 展示了 SimpleDB 支持的表和三个基本操作符的扫描构造函数。
图 8.7 SimpleDB 实现 Scan 接口的构造函数 API (The API of the SimpleDB constructors that implement Scan)
Scan 接口
-
public TableScan(Transaction tx, String filename, Layout layout);- 创建一个
TableScan,用于访问存储在磁盘上的实际表。
- 创建一个
-
public SelectScan(Scan s, Predicate pred);- 创建一个
SelectScan,它基于底层Scan(s) 并应用一个谓词 (pred) 进行选择。
- 创建一个
-
public ProjectScan(Scan s, List<String> fldlist);- 创建一个
ProjectScan,它基于底层Scan(s) 并只选择指定的字段列表 (fldlist)。
- 创建一个
-
public ProductScan(Scan s1, Scan s2);- 创建一个
ProductScan,它将两个底层Scan(s1和s2) 进行笛卡尔积操作。
- 创建一个
SelectScan 构造函数接受两个参数:一个底层扫描 (underlying scan) 和一个谓词。底层扫描是选择操作符的输入。由于 Scan 是一个接口,SelectScan 对象不知道其输入是存储的表还是另一个查询的输出。这种情况对应于关系操作符的输入可以是任何表或查询的事实。
传递给 SelectScan 构造函数的选择谓词的类型是 Predicate。8.6 节讨论了 SimpleDB 如何处理谓词的细节;在此之前,我将对此问题保持模糊。
查询树是通过组合扫描构建的。树的每个节点都将有一个扫描。例如,图 8.8 给出了图 8.2 查询树的 SimpleDB 代码(省略了选择谓词的细节)。Scan 变量 s1、s2 和 s3 各自对应于查询树中的一个节点。树是自底向上构建的:首先创建表扫描,然后是选择扫描,最后是投影扫描。变量 s3 包含了最终的查询树。while 循环遍历 s3,打印每个学生姓名。
图 8.8 将图 8.2 表示为扫描 (Representing Fig. 8.2 as a scan)
// 假设 db 已初始化
Transaction tx = db.newTx(); // 开启一个新事务
MetadataMgr mdm = db.MetadataMgr(); // 获取元数据管理器
// the STUDENT node (STUDENT 节点)
// 获取 "student" 表的布局
Layout layout = mdm.getLayout("student", tx);
// 创建一个 TableScan 来访问 "student" 表
Scan s1 = new TableScan(tx, "student", layout);
// the Select node (Select 节点)
// 假设 Predicate 对象 pred 已经创建,其谓词是 "majorid=10"
Predicate pred = /* new Predicate(...) */; // majorid=10
// 创建一个 SelectScan,以 s1 为输入,并应用 pred 谓词
Scan s2 = new SelectScan(s1, pred);
// the Project node (Project 节点)
// 定义要投影的字段列表,这里是 "sname"
List<String> c = Arrays.asList("sname");
// 创建一个 ProjectScan,以 s2 为输入,并只选择 "sname" 字段
Scan s3 = new ProjectScan(s2, c);
// 遍历最终的查询结果并打印
s3.beforeFirst(); // 定位到第一条记录之前
while (s3.next()) { // 遍历所有记录
System.out.println(s3.getString("sname")); // 打印学生姓名
}
s3.close(); // 关闭扫描器
// 注意:原图中此处的 s3.close() 和 System.out.println() 位置有误,
// getString 应该在 next() 内部调用,且 close() 应该在遍历结束后。
// 上述代码已修正为更合理的逻辑。
图 8.9 将图 8.4 表示为扫描 (Representing Fig. 8.4 as a scan)
// 假设 db 已初始化
Transaction tx = db.newTx(); // 开启一个新事务
MetadataMgr mdm = db.MetadataMgr(); // 获取元数据管理器
// the STUDENT node (STUDENT 节点)
// 获取 "student" 表的布局
Layout layout1 = mdm.getLayout("student", tx);
// 创建 TableScan 来访问 "student" 表
Scan s1 = new TableScan(tx, "student", layout1);
// the DEPT node (DEPT 节点)
// 获取 "dept" 表的布局
Layout layout2 = mdm.getLayout("dept", tx);
// 创建 TableScan 来访问 "dept" 表
Scan s2 = new TableScan(tx, "dept", layout2);
// the Product node (Product 节点)
// 创建 ProductScan,将 s1 和 s2 进行笛卡尔积操作
Scan s3 = new ProductScan(s1, s2);
// the Select node (Select 节点)
// 假设 Predicate 对象 pred 已经创建,其谓词是 "majorid=did"
Predicate pred = /* new Predicate(...) */; // majorid=did
// 创建 SelectScan,以 s3 为输入,并应用 pred 谓词
Scan s4 = new SelectScan(s3, pred);
// 遍历最终的查询结果并打印
s4.beforeFirst(); // 定位到第一条记录之前
while (s4.next()) { // 遍历所有记录
// 打印学生姓名、毕业年份和部门名称
System.out.println(s4.getString("sname") + ", " +
s4.getString("gradyear") + ", " +
s4.getString("dname"));
}
s4.close(); // 关闭扫描器
代码包含四个扫描,因为查询树有四个节点。变量 s4 包含了最终的查询树。请注意 while 循环与之前的代码几乎相同。为了节省空间,循环只打印每个输出记录的三个字段值,但可以很容易地修改以包含所有六个字段值。
8.3 更新扫描 (Update Scans)
查询定义了一个虚拟表 (virtual table)。Scan 接口有允许客户端从这个虚拟表读取数据的方法,但不能更新它。并非所有扫描都可以有意义地更新。如果扫描中的每个输出记录 r 在底层数据库表中都有一个对应的记录 r0,则该扫描是可更新的 (updatable)。在这种情况下,对 r 的更新被定义为对 r0 的更新。
可更新扫描支持 UpdateScan 接口;参见 图 8.10。该接口的前五个方法是基本的修改操作。另外两个方法涉及扫描当前记录底层存储记录的标识符。getRid 方法返回此标识符,moveToRid 将扫描定位到指定的存储记录。
图 8.10 SimpleDB UpdateScan 接口 (The SimpleDB UpdateScan interface)
public interface UpdateScan extends Scan {
// 设置指定字段的整数值
public void setInt(String fldname, int val);
// 设置指定字段的字符串值
public void setString(String fldname, String val);
// 设置指定字段的 Constant 值(通用类型)
public void setVal(String fldname, Constant val);
// 在当前位置插入一条新记录
public void insert();
// 删除当前记录
public void delete();
// 获取当前记录的记录 ID (Record ID)
public RID getRid();
// 将扫描器移动到指定的记录 ID
public void moveToRid(RID rid);
}
SimpleDB 中只有两个类实现了 UpdateScan:TableScan 和 SelectScan。作为它们使用的一个示例,考虑 图 8.11。
图 8.11 将 SQL UPDATE 语句表示为更新扫描。(a) 修改第 53 节学生成绩的 SQL 语句,(b) 对应语句的 SimpleDB 代码 (Representing an SQL update statement as an update scan. (a) An SQL statement to modify the grades of students in section 53, (b) the SimpleDB code corresponding to the statement)
(a) SQL 语句:
UPDATE ENROLL
SET Grade = 'C'
WHERE SectionId = 53;
(b) SimpleDB 代码:
// 假设 db 已初始化
Transaction tx = db.newTx(); // 开启一个新事务
MetadataMgr mdm = db.MetadataMgr(); // 获取元数据管理器
// 获取 "enroll" 表的布局
Layout layout = mdm.getLayout("enroll", tx);
// 创建一个 TableScan 来访问 "enroll" 表
Scan s1 = new TableScan(tx, "enroll", layout);
// 假设 Predicate 对象 pred 已经创建,其谓词是 "SectionId=53"
Predicate pred = /* new Predicate(...) */; // SectionId=53
// 创建一个 SelectScan,以 s1 为输入,并应用 pred 谓词。
// 注意这里强制转换为 UpdateScan,因为需要进行更新操作。
UpdateScan s2 = new SelectScan(s1, pred);
// 遍历所有满足条件(SectionId=53)的记录
s2.beforeFirst(); // 定位到第一条记录之前
while (s2.next()) {
s2.setString("grade", "C"); // 将 "grade" 字段的值设置为 "C"
}
s2.close(); // 关闭扫描器
tx.commit(); // 提交事务
(a) 部分显示了一个 SQL 语句,它更改了选修第 53 节课的每个学生的成绩,(b) 部分给出了实现此语句的代码。该代码首先创建了一个针对第 53 节所有注册记录的选择扫描;然后它遍历扫描,更改每条记录的成绩。
变量 s2 调用 setString 方法,因此它必须被声明为 UpdateScan。另一方面,SelectScan 构造函数的第一个参数是一个 Scan,这意味着它不需要被声明为 UpdateScan。相反,s2 的 setString 方法的代码将把其底层扫描(即 s1)强制转换为 UpdateScan;如果该扫描不可更新,则会抛出 ClassCastException。
8.4 实现扫描 (Implementing Scans)
SimpleDB 引擎包含四个 Scan 类:TableScan 类以及用于 select、project 和 product 操作符的类。第 6 章已经探讨了 TableScan。以下小节将讨论这三个操作符类。
8.4.1 选择扫描 (Select Scans)
SelectScan 的代码如 图 8.12 所示。构造函数持有其底层输入表的扫描 (scan of its underlying input table)。扫描的当前记录与其底层扫描的当前记录相同,这意味着大多数方法可以通过简单地调用该扫描的相应方法来实现。
唯一不平凡的方法是 next()。此方法的任务是建立一个新的当前记录。代码循环遍历底层扫描,寻找满足谓词的记录。如果找到这样的记录,它就成为当前记录,并且该方法返回 true。如果没有这样的记录,则 while 循环将完成,并且该方法将返回 false。
选择扫描是可更新的 (updatable)。UpdateScan 方法假定底层扫描也是可更新的;特别是,它们假定可以将底层扫描强制转换为 UpdateScan 而不会引起 ClassCastException。由于 SimpleDB 更新规划器创建的扫描只涉及表扫描和选择扫描,因此不应发生此类异常。
图 8.12 SimpleDB SelectScan 类的代码 (The code for the SimpleDB class SelectScan)
public class SelectScan implements UpdateScan { // SelectScan 实现了 UpdateScan 接口
private Scan s; // 底层扫描
private Predicate pred; // 选择谓词
// 构造函数
public SelectScan(Scan s, Predicate pred) {
this.s = s;
this.pred = pred;
}
// Scan 方法
@Override
public void beforeFirst() {
s.beforeFirst(); // 将底层扫描重置到起始位置
}
@Override
public boolean next() {
// 循环遍历底层扫描,直到找到满足谓词的记录
while (s.next()) {
if (pred.isSatisfied(s)) { // 如果当前记录满足谓词
return true; // 则该记录成为 SelectScan 的当前记录,并返回 true
}
}
return false; // 如果遍历完所有记录都没有找到满足谓词的,则返回 false
}
@Override
public int getInt(String fldname) {
return s.getInt(fldname); // 直接委托给底层扫描
}
@Override
public String getString(String fldname) {
return s.getString(fldname); // 直接委托给底层扫描
}
@Override
public Constant getVal(String fldname) {
return s.getVal(fldname); // 直接委托给底层扫描
}
@Override
public boolean hasField(String fldname) {
return s.hasField(fldname); // 直接委托给底层扫描
}
@Override
public void close() {
s.close(); // 关闭底层扫描
}
// UpdateScan 方法 (所有更新操作都通过向下转型并委托给底层可更新扫描实现)
@Override
public void setInt(String fldname, int val) {
// 将底层 Scan 强制转换为 UpdateScan
UpdateScan us = (UpdateScan) s;
us.setInt(fldname, val); // 委托给底层 UpdateScan
}
@Override
public void setString(String fldname, String val) {
UpdateScan us = (UpdateScan) s;
us.setString(fldname, val);
}
@Override
public void setVal(String fldname, Constant val) {
UpdateScan us = (UpdateScan) s;
us.setVal(fldname, val);
}
@Override
public void delete() {
UpdateScan us = (UpdateScan) s;
us.delete();
}
@Override
public void insert() {
UpdateScan us = (UpdateScan) s;
us.insert();
}
@Override
public RID getRid() {
UpdateScan us = (UpdateScan) s;
return us.getRid();
}
@Override
public void moveToRid(RID rid) {
UpdateScan us = (UpdateScan) s;
us.moveToRid(rid);
}
}
8.4.2 投影扫描 (Project Scans)
ProjectScan 的代码如 图 8.13 所示。输出字段列表被传递给构造函数,并用于实现 hasField 方法。其他方法只是将其请求转发到底层扫描的相应方法。getVal、getInt 和 getString 方法检查指定的字段名是否在字段列表中;如果不在,则会抛出异常。
ProjectScan 类没有实现 UpdateScan,尽管投影是可更新的。练习 8.12 要求您完成此实现。
图 8.13 SimpleDB ProjectScan 类的代码 (The code for the SimpleDB class ProjectScan)
public class ProjectScan implements Scan { // ProjectScan 实现了 Scan 接口,但不是 UpdateScan
private Scan s; // 底层扫描
private Collection<String> fieldlist; // 要投影的字段列表
// 构造函数
public ProjectScan(Scan s, List<String> fieldlist) {
this.s = s;
this.fieldlist = fieldlist;
}
@Override
public void beforeFirst() {
s.beforeFirst(); // 直接委托给底层扫描
}
@Override
public boolean next() {
return s.next(); // 直接委托给底层扫描,ProjectScan 不改变记录的遍历顺序
}
// 获取整数值,如果字段不在投影列表中则抛出异常
@Override
public int getInt(String fldname) {
if (hasField(fldname)) {
return s.getInt(fldname);
} else {
throw new RuntimeException("field not found.");
}
}
// 获取字符串值,如果字段不在投影列表中则抛出异常
@Override
public String getString(String fldname) {
if (hasField(fldname)) {
return s.getString(fldname);
} else {
throw new RuntimeException("field not found.");
}
}
// 获取 Constant 值,如果字段不在投影列表中则抛出异常
@Override
public Constant getVal(String fldname) {
if (hasField(fldname)) {
return s.getVal(fldname);
} else {
throw new RuntimeException("field not found.");
}
}
// 检查字段是否在投影列表中
@Override
public boolean hasField(String fldname) {
return fieldlist.contains(fldname);
}
@Override
public void close() {
s.close(); // 关闭底层扫描
}
}
8.4.3 乘积扫描 (Product Scans)
ProductScan 的代码如 图 8.14 所示。乘积扫描需要能够遍历其底层扫描 s1 和 s2 的所有可能记录组合。它通过从 s1 的第一条记录开始,并遍历 s2 的每条记录,然后移动到 s1 的第二条记录并遍历 s2,以此类推。从概念上讲,它就像有一个嵌套循环 (nested loop),外层循环遍历 s1,内层循环遍历 s2。
图 8.14 SimpleDB ProductScan 类的代码 (The code for the SimpleDB class ProductScan)
public class ProductScan implements Scan { // ProductScan 实现了 Scan 接口
private Scan s1, s2; // 两个底层扫描
// 构造函数
public ProductScan(Scan s1, Scan s2) {
this.s1 = s1;
this.s2 = s2;
// 在构造时尝试移动到 s1 的第一条记录
// 这一步是关键,因为它保证了 next() 方法在第一次调用时能正确处理 s2 的遍历
s1.beforeFirst(); // 确保 s1 在开始位置
s1.next(); // 移动到 s1 的第一条记录
s2.beforeFirst(); // 确保 s2 在开始位置
}
@Override
public void beforeFirst() {
s1.beforeFirst(); // 重置 s1 到起始位置
s1.next(); // 移动到 s1 的第一条记录
s2.beforeFirst(); // 重置 s2 到起始位置
}
@Override
public boolean next() {
if (s2.next()) { // 尝试移动到 s2 的下一条记录
return true; // 如果成功,说明找到了一个新的组合,返回 true
} else {
// s2 已经遍历完毕,需要重置 s2 并移动到 s1 的下一条记录
s2.beforeFirst(); // 重置 s2 到起始位置
// 尝试移动到 s2 的第一条记录,同时检查 s1 是否有下一条记录
return s2.next() && s1.next();
// 如果 s1.next() 返回 false,则说明 s1 也遍历完毕,整个乘积扫描结束
}
}
// 获取字段的整数值,首先检查 s1 是否包含该字段
@Override
public int getInt(String fldname) {
if (s1.hasField(fldname)) {
return s1.getInt(fldname);
} else {
return s2.getInt(fldname); // 否则,从 s2 获取
}
}
// 获取字段的字符串值,首先检查 s1 是否包含该字段
@Override
public String getString(String fldname) {
if (s1.hasField(fldname)) {
return s1.getString(fldname);
} else {
return s2.getString(fldname);
}
}
// 获取字段的 Constant 值,首先检查 s1 是否包含该字段
@Override
public Constant getVal(String fldname) {
if (s1.hasField(fldname)) {
return s1.getVal(fldname);
} else {
return s2.getVal(fldname);
}
}
// 检查字段是否存在于任何一个底层扫描中
@Override
public boolean hasField(String fldname) {
return s1.hasField(fldname) || s2.hasField(fldname);
}
@Override
public void close() {
s1.close(); // 关闭 s1
s2.close(); // 关闭 s2
}
}
next 方法实现这种“嵌套循环”思想如下。每次调用 next 都会移动到 s2 的下一条记录。如果 s2 有这样的记录,它就可以返回 true。如果不是,则 s2 的迭代完成,因此该方法移动到 s1 的下一条记录和 s2 的第一条记录。如果这可能,它返回 true;如果 s1 没有更多记录,则扫描完成,next 返回 false。
getVal、getInt 和 getString 方法只是访问相应底层扫描的字段。每个方法都检查指定字段是否在扫描 s1 中。如果是,则使用 s1 访问该字段;否则,使用 s2 访问该字段。
通过这些扫描实现,SimpleDB 能够以模块化的方式处理关系代数操作,并支持复杂的查询执行。
8.5 管道化查询处理 (Pipelined Query Processing)
这三个关系代数操作符的实现有两个共同特征:
- 它们根据需要,一次生成一个输出记录。
- 它们不保存其输出记录,也不保存任何中间计算结果。
这种实现称为管道化 (pipelined)。本节分析管道化实现及其特性。
考虑一个 TableScan 对象。它持有一个记录页 (record page),该记录页持有一个缓冲区,该缓冲区持有一个包含当前记录的页面。当前记录只是该页面中的一个位置。记录不需要从其页面中移除;如果客户端请求字段的值,则记录管理器只需从页面中提取该值并将其返回给客户端。每次调用 next 都会将表扫描定位到其下一条记录,这可能会导致它持有不同的记录页。
现在考虑一个 SelectScan 对象。每次调用其 next 方法都会重复调用其底层扫描的 next,直到底层扫描的当前记录满足谓词。但当然,实际上没有“当前记录”——如果底层扫描是表扫描,那么当前记录只是表扫描所持有的页面中的一个位置。如果底层扫描是另一种类型的扫描(例如 图 8.4 和 8.9 中的乘积扫描),那么当前记录的值是由该节点子树中的表扫描的当前记录确定的。
每次管道化扫描处理另一个 next 调用时,它都会从上次停下的地方开始搜索。因此,扫描只从其底层扫描请求所需数量的记录来确定下一个输出记录。
管道化扫描不跟踪它已选择的记录。因此,如果客户端第二次请求记录,扫描将需要重新执行整个搜索。
图 8.15 包含多个选择节点的查询树 (A query tree containing multiple select nodes)
project {SName}
|
select GradYear=2020
|
select MajorId=10
|
STUDENT
“管道化”一词指的是方法调用沿着查询树向下流动,以及结果值沿着树向上流动。例如,考虑对 getInt 方法的调用。树中的每个节点都会将该调用传递给其子节点之一,直到到达叶节点。该叶节点(即表扫描)从其页面中提取所需的值并将其返回到树的上方。或者考虑对 next 方法的调用。每个节点对它的子节点进行一个或多个 next 调用(在乘积节点的情况下,可能还有 beforeFirst),直到它确信其子节点包含下一条记录的内容。然后它向其父节点返回成功(如果不存在这样的记录,则返回失败)。
管道化实现可以非常高效。例如,考虑 图 8.15 的查询树,它检索 2020 年毕业的专业为 10 的学生的姓名。
该树中的投影和选择节点除了表扫描所需的块访问之外,不会对 STUDENT 表产生额外的块访问。为了说明原因,首先考虑投影节点。每次对该节点的 next 调用将简单地调用其子节点的 next 并返回该节点的返回值。换句话说,投影节点不会改变查询其余部分执行的块访问次数。
现在考虑选择节点。对外部选择节点的 next 调用将调用内部选择节点的 next。内部节点将重复调用其子节点的 next,直到当前记录满足谓词“MajorId = 10”。然后内部选择节点返回 true,外部选择节点检查当前记录。如果其毕业年份不是 2020,则外部节点将再次调用内部节点的 next 并等待另一个当前记录。外部选择节点返回 true 的唯一方式是该记录同时满足两个谓词。每次外部节点调用 next 时,此过程都会继续,底层表扫描不断移动到其下一条记录,直到两个谓词都满足。当表扫描识别出没有更多 STUDENT 记录时,其 next 方法将返回 false,并且 false 值将传播到树的上方。换句话说,STUDENT 只被扫描一次,这与查询只执行一个表扫描完全相同。由此可见,此查询中的选择节点是无成本的 (cost-free)。
尽管管道化实现在这些情况下非常高效,但在其他情况下它们并不那么好。一个这样的情况是当选择节点位于乘积节点的右侧时,它将被多次执行。与其一遍又一遍地执行选择,不如使用一种具体化 (materializes) 输出记录并将其存储在临时表中的实现。此类实现是第 13 章的主题。
8.6 谓词 (Predicates)
谓词 (predicate) 指定一个条件,对于给定扫描的每一行返回 true 或 false。如果条件返回 true,则称该行满足谓词。SQL 谓词的结构如下:
- 谓词 (Predicate) 是一个项 (term) 或多个项的布尔组合。
- 项 (Term) 是两个表达式 (expression) 之间的比较。
- 表达式 (Expression) 由常量和字段名上的操作组成。
- 常量 (Constant) 是来自预定类型集的值,例如整数和字符串。
例如,考虑标准 SQL 中的以下谓词:
( GradYear > 2021 or MOD(GradYear,4)=0 ) and MajorId=DId
此谓词由三个项(粗体显示)组成。前两个项将字段名 GradYear(或 GradYear 的函数)与一个常量进行比较,第三个项比较两个字段名。每个项包含两个表达式。例如,第二个项包含表达式 MOD(GradYear,4) 和 0。
SimpleDB 大大简化了允许的常量、表达式、项和谓词。SimpleDB 常量只能是整数或字符串,表达式只能是常量或字段名,项只能比较表达式是否相等,谓词只能创建项的合取 (conjuncts)。练习 8.7-8.9 要求您扩展 SimpleDB 谓词以使其更具表达性。
考虑以下谓词:
SName = 'joe' and MajorId = DId
图 8.16 的代码片段展示了如何在 SimpleDB 中创建此谓词。请注意谓词是如何由内而外创建的,从常量和表达式开始,然后是项,最后是谓词。
图 8.16 创建谓词的 SimpleDB 代码 (SimpleDB code to create a predicate)
// 创建表达式和常量
Expression lhs1 = new Expression("SName"); // 左侧表达式:字段名 "SName"
Constant c = new Constant("joe"); // 常量 "joe"
Expression rhs1 = new Expression(c); // 右侧表达式:常量 "joe"
// 创建第一个项:SName = 'joe'
Term t1 = new Term(lhs1, rhs1);
// 创建第二个表达式和常量
Expression lhs2 = new Expression("MajorId"); // 左侧表达式:字段名 "MajorId"
Expression rhs2 = new Expression("DId"); // 右侧表达式:字段名 "DId"
// 创建第二个项:MajorId = DId
Term t2 = new Term(lhs2, rhs2);
// 创建谓词,首先将每个项包装成一个单独的谓词
Predicate pred1 = new Predicate(t1);
Predicate pred2 = new Predicate(t2);
// 将两个谓词合取(AND 操作)
pred1.conjoinWith(pred2); // pred1 现在表示 "SName = 'joe' AND MajorId = DId"
图 8.17 给出了 Constant 类的代码。每个 Constant 对象包含一个 Integer 变量和一个 String 变量。根据调用了哪个构造函数,只有一个变量将是非 null 的。equals、compareTo、hashCode 和 toString 方法使用那个非 null 的变量。
图 8.17 Constant 类 (The class Constant)
public class Constant implements Comparable<Constant> {
private Integer ival = null; // 用于存储整数常量
private String sval = null; // 用于存储字符串常量
// 整数常量构造函数
public Constant(Integer ival) {
this.ival = ival;
}
// 字符串常量构造函数
public Constant(String sval) {
this.sval = sval;
}
// 返回整数值
public int asInt() {
return ival;
}
// 返回字符串值
public String asString() {
return sval;
}
// 比较两个 Constant 对象是否相等
public boolean equals(Object obj) {
Constant c = (Constant) obj; // 将 obj 强制转换为 Constant 类型
// 如果是整数类型,则比较整数值;否则比较字符串值
return (ival != null) ? ival.equals(c.ival) : sval.equals(c.sval);
}
// 比较两个 Constant 对象的大小
public int compareTo(Constant c) {
// 如果是整数类型,则比较整数值;否则比较字符串值
return (ival != null) ? ival.compareTo(c.ival) : sval.compareTo(c.sval);
}
// 返回对象的哈希码
public int hashCode() {
// 如果是整数类型,则返回整数的哈希码;否则返回字符串的哈希码
return (ival != null) ? ival.hashCode() : sval.hashCode();
}
// 返回对象的字符串表示
public String toString() {
// 如果是整数类型,则返回整数的字符串表示;否则返回字符串的字符串表示
return (ival != null) ? ival.toString() : sval.toString();
}
}
图 8.18 Expression 类 (The class Expression)
public class Expression {
private Constant val = null; // 用于存储常量值
private String fldname = null; // 用于存储字段名
// 常量表达式构造函数
public Expression(Constant val) {
this.val = val;
}
// 字段名表达式构造函数
public Expression(String fldname) {
this.fldname = fldname;
}
// 检查表达式是否为字段名
public boolean isFieldName() {
return fldname != null;
}
// 返回表达式的常量值
public Constant asConstant() {
return val;
}
// 返回表达式的字段名
public String asFieldName() {
return fldname;
}
// 评估表达式的值
// 如果是常量,则直接返回常量值;如果是字段名,则从扫描中获取字段值
public Constant evaluate(Scan s) {
return (val != null) ? val : s.getVal(fldname);
}
// 检查表达式是否适用于给定的 Schema
// 如果是常量,则始终适用;如果是字段名,则检查 Schema 是否包含该字段
public boolean appliesTo(Schema sch) {
return (val != null) ? true : sch.hasField(fldname);
}
// 返回表达式的字符串表示
public String toString() {
return (val != null) ? val.toString() : fldname;
}
}
Expression 类的代码如 图 8.18 所示。它也有两个构造函数,一个用于常量表达式,一个用于字段名表达式。每个构造函数都为其关联的变量赋值。isFieldName 方法提供了一种方便的方式来确定表达式是否表示字段名。evaluate 方法返回表达式相对于扫描的当前输出记录的值。如果表达式是常量,则扫描无关紧要,该方法只返回常量。如果表达式是字段,则该方法从扫描中返回字段的值。appliesTo 方法由查询规划器使用,以确定表达式的作用域。
图 8.19 Term 类 (The code for the SimpleDB class Term)
public class Term {
private Expression lhs, rhs; // 左侧和右侧表达式
// 构造函数
public Term(Expression lhs, Expression rhs) {
this.lhs = lhs;
this.rhs = rhs;
}
// 检查当前扫描记录是否满足该项
public boolean isSatisfied(Scan s) {
Constant lhsval = lhs.evaluate(s); // 评估左侧表达式
Constant rhsval = rhs.evaluate(s); // 评估右侧表达式
return rhsval.equals(lhsval); // 检查两者是否相等
}
// 检查该项是否适用于给定的 Schema
public boolean appliesTo(Schema sch) {
return lhs.appliesTo(sch) && rhs.appliesTo(sch); // 检查左右表达式是否都适用
}
// 计算该项的筛选因子(降低因子),用于查询优化器
public int reductionFactor(Plan p) {
String lhsName, rhsName;
// 如果左右都是字段名
if (lhs.isFieldName() && rhs.isFieldName()) {
lhsName = lhs.asFieldName();
rhsName = rhs.asFieldName();
// 返回两个字段中不同值数量的最大值
return Math.max(p.distinctValues(lhsName), p.distinctValues(rhsName));
}
// 如果只有左侧是字段名
if (lhs.isFieldName()) {
lhsName = lhs.asFieldName();
return p.distinctValues(lhsName); // 返回左侧字段的不同值数量
}
// 如果只有右侧是字段名
if (rhs.isFieldName()) {
rhsName = rhs.asFieldName();
return p.distinctValues(rhsName); // 返回右侧字段的不同值数量
}
// 否则,该项比较的是常量
if (lhs.asConstant().equals(rhs.asConstant())) {
return 1; // 如果常量相等,筛选因子为 1 (所有记录都满足)
} else {
return Integer.MAX_VALUE; // 如果常量不相等,筛选因子为极大值 (没有记录满足)
}
}
// 如果该项将指定字段与常量相等,则返回该常量
public Constant equatesWithConstant(String fldname) {
if (lhs.isFieldName() && lhs.asFieldName().equals(fldname) && !rhs.isFieldName()) {
return rhs.asConstant(); // 左侧是字段名,右侧是常量,且字段名匹配
} else if (rhs.isFieldName() && rhs.asFieldName().equals(fldname) && !lhs.isFieldName()) {
return lhs.asConstant(); // 右侧是字段名,左侧是常量,且字段名匹配
} else {
return null; // 不匹配或两者都不是字段名/常量
}
}
// 如果该项将指定字段与另一个字段相等,则返回另一个字段名
public String equatesWithField(String fldname) {
if (lhs.isFieldName() && lhs.asFieldName().equals(fldname) && rhs.isFieldName()) {
return rhs.asFieldName(); // 左侧是字段名,右侧也是字段名,且左侧字段名匹配
} else if (rhs.isFieldName() && rhs.asFieldName().equals(fldname) && lhs.isFieldName()) {
return lhs.asFieldName(); // 右侧是字段名,左侧也是字段名,且右侧字段名匹配
} else {
return null; // 不匹配或两者都不是字段名
}
}
// 返回项的字符串表示
public String toString() {
return lhs.toString() + "=" + rhs.toString();
}
}
SimpleDB 中的项 (Terms) 由 Term 接口实现,其代码如 图 8.19 所示。其构造函数接受两个参数,表示左侧和右侧表达式。最重要的方法是 isSatisfied,如果两个表达式在给定扫描中评估为相同的值,则返回 true。其余方法帮助查询规划器确定项的效果和作用域。例如,reductionFactor 方法确定将满足谓词的预期记录数,并将在第 10 章中更详细地讨论。equatesWithConstant 和 equatesWithField 方法帮助查询规划器决定何时使用索引,并将在第 15 章中讨论。
图 8.20 SimpleDB Predicate 类的代码
public class Predicate {
private List<Term> terms = new ArrayList<Term>();
public Predicate() {}
public Predicate(Term t) {
terms.add(t);
}
public void conjoinWith(Predicate pred) {
terms.addAll(pred.terms);
}
public boolean isSatisfied(Scan s) {
for (Term t : terms)
if (!t.isSatisfied(s))
return false;
return true;
}
public int reductionFactor(Plan p) {
int factor = 1;
for (Term t : terms)
factor *= t.reductionFactor(p);
return factor;
}
public Predicate selectSubPred(Schema sch) {
Predicate result = new Predicate();
for (Term t : terms)
if (t.appliesTo(sch))
result.terms.add(t);
if (result.terms.size() == 0)
return null;
else
return result;
}
public Predicate joinSubPred(Schema sch1, Schema sch2) {
Predicate result = new Predicate();
Schema newsch = new Schema();
newsch.addAll(sch1);
newsch.addAll(sch2);
for (Term t : terms)
if (!t.appliesTo(sch1) && !t.appliesTo(sch2) && t.appliesTo(newsch))
result.terms.add(t);
if (result.terms.size() == 0)
return null;
else
return result;
}
public Constant equatesWithConstant(String fldname) {
for (Term t : terms) {
Constant c = t.equatesWithConstant(fldname);
if (c != null)
return c;
}
return null;
}
public String equatesWithField(String fldname) {
for (Term t : terms) {
String s = t.equatesWithField(fldname);
if (s != null)
return s;
}
return null;
}
public String toString() {
Iterator<Term> iter = terms.iterator();
if (!iter.hasNext())
return "";
String result = iter.next().toString();
while (iter.hasNext())
result += " and " + iter.next().toString();
return result;
}
}
Predicate 类的代码如 图 8.20 所示。谓词实现为项的列表 (list of terms),谓词通过调用其每个项的相应方法来响应其方法。该类有两个构造函数。一个构造函数没有参数,并创建一个没有项的谓词。这样的谓词总是满足的,对应于谓词 true。另一个构造函数创建一个包含单个项的谓词。conjoinWith 方法将参数谓词中的项添加到指定的谓词中。
8.7 章总结 (Chapter Summary)
-
关系代数查询 (relational algebra query) 由操作符 (operators) 组成。每个操作符执行一个专门的任务。查询中操作符的组合可以表示为查询树 (query tree)。
-
本章描述了对理解和翻译 SimpleDB 版本 SQL 有用的三个操作符。它们是:
- 选择 (select):其输出表与输入表具有相同的列,但删除了一些行。
- 投影 (project):其输出表与输入表具有相同的行,但删除了一些列。
- 乘积 (product):其输出表由其两个输入表的所有可能记录组合组成。
-
扫描 (scan) 是一个表示关系代数查询树的对象。每个关系操作符都有一个相应的类来实现
Scan接口;这些类的对象构成了查询树的内部节点。还有一个用于表的扫描类,其对象构成了树的叶子。 -
Scan方法与TableScan中的方法基本相同。客户端通过扫描进行迭代,从一个输出记录移动到下一个输出记录并检索字段值。扫描通过适当地移动记录文件和比较值来管理查询的实现。 -
如果扫描中的每条记录
r在某个底层数据库表中都有一个对应的记录r0,则该扫描是可更新的 (updatable)。在这种情况下,对虚拟记录r的更新被定义为对存储记录r0的更新。 -
每个扫描类的方法都实现了该操作符的意图。例如:
- 选择扫描 (select scan) 检查其底层扫描中的每条记录,并只返回那些满足其谓词 (predicate) 的记录。
- 乘积扫描 (product scan) 为其两个底层扫描的每种记录组合返回一条记录。
- 表扫描 (table scan) 为指定表打开一个记录文件,根据需要锁定缓冲区并获取锁。
-
这些扫描实现被称为管道化实现 (pipelined implementations)。管道化实现不会尝试预读、缓存、排序或以其他方式预处理其数据。
-
管道化实现不构造输出记录。查询树中的每个叶子都是一个表扫描 (table scan),其中包含一个持有该表当前记录的缓冲区。“操作的当前记录”是由每个缓冲区中的记录确定的。获取字段值的请求沿着树向下定向到适当的表扫描;结果从表扫描返回到根节点。
-
使用管道化实现的扫描以按需 (need-to-know) 的方式操作。每个扫描将只从其子节点请求确定其下一条记录所需的记录数量。
8.8 建议阅读(Suggested Reading)
几乎所有数据库入门教材都定义了关系代数,尽管每本教材的语法倾向于不同。关于关系代数及其表达能力的详细介绍,可以在 Atzeni 和 DeAntonellis (1992) 的著作中找到。该书还介绍了关系演算,它是一种基于谓词逻辑的查询语言。关系演算的有趣之处在于,它可以扩展以允许递归查询(即,查询定义中也提及输出表的查询)。递归关系演算被称为 Datalog,与 Prolog 编程语言相关。关于 Datalog 及其表达能力的讨论也出现在 Atzeni 和 DeAntonellis (1992) 的著作中。
管道化查询处理的话题只是查询处理难题的一小部分,其中还包括后面章节的主题。Graefe (1993) 的文章包含了关于查询处理技术的全面信息;第 1 节详细讨论了扫描和管道化处理。Chaudhuri (1998) 的文章除了统计数据收集和优化之外,还讨论了查询树。
- Atzeni, P., & DeAntonellis, V. (1992). 关系数据库理论 (Relational database theory). Upper Saddle River, NJ: Prentice-Hall.
- Chaudhuri, S. (1998). 关系系统中查询优化概述 (An overview of query optimization in relational systems). ACM 数据库系统原理会议论文集 (In Proceedings of the ACM Principles of Database Systems Conference) (第 34–43 页).
- Graefe, G. (1993). 大型数据库的查询评估技术 (Query evaluation techniques for large databases). ACM 计算概览 (ACM Computing Surveys), 25(2), 73–170.
8.9 练习(Exercises)
概念练习(Conceptual Exercises)
8.1. 如果乘积操作的任一输入为空,其输出是什么?
8.2. 使用图 8.9 作为模板,将以下查询实现为扫描:
select sname, dname, grade from STUDENT, DEPT, ENROLL, SECTION where SId=StudentId and SectId=SectionId and DId=MajorId and YearOffered=2020
8.3. 考虑图 8.9 的代码。
(a) 事务需要获得哪些锁才能执行此代码?
(b) 对于这些锁中的每一个,举例说明导致代码等待该锁的情况。
8.4. 考虑 ProductScan 的代码。
(a) 当第一个底层扫描没有记录时,可能会出现什么问题?代码应该如何修复?
(b) 解释为什么当第二个底层扫描没有记录时不会出现问题。
8.5. 假设你想通过 STUDENT 与自身进行乘积运算来查找所有学生对。
(a) 一种方法是在 STUDENT 上创建一个表扫描,并在乘积中两次使用它,如下面代码片段所示:
Layout layout = mdm.getLayout("student", tx);
Scan s1 = new TableScan(tx, "student", layout);
Scan s2 = new ProductScan(s1, s1);
解释为什么在执行扫描时,这会产生不正确(和奇怪)的行为。
(b) 更好的方法是在 STUDENT 上创建两个不同的表扫描,并在它们上创建乘积扫描。这会返回 STUDENT 记录的所有组合,但有一个问题。它是什么?
编程练习(Programming Exercises)
8.6. ProjectScan 中的 getVal、getInt 和 getString 方法会检查它们的参数字段名是否有效。其他扫描类都没有这样做。对于其他每个扫描类:
(a) 说明如果使用无效字段调用这些方法,会发生什么问题(以及在哪个方法中)。
(b) 修复 SimpleDB 代码,使其抛出适当的异常。
8.7. 目前,SimpleDB 仅支持整数和字符串常量。
(a) 修改 SimpleDB 以支持其他类型的常量,例如短整数、字节数组和日期。
(b) 练习 3.17 要求你修改 Page 类以具有短整数、日期等类型的 get/set 方法。如果你已经完成了这个练习,请在 Scan 和 UpdateScan(及其各种实现类),以及记录管理器、事务管理器和缓冲区管理器中添加类似的 get/set 方法。然后适当地修改 getVal 和 setVal 方法。
8.8. 修改表达式以处理整数的算术运算符。
8.9. 修改 Term 类以处理比较运算符 < 和 >。
8.10. 修改 Predicate 类以处理布尔连接词 and、or 和 not 的任意组合。
8.11. 在练习 6.13 中,你扩展了 SimpleDB 记录管理器以处理数据库空值。现在扩展查询处理器以处理空值。特别是:
- 适当地修改
Constant类。 - 修改
TableScan中的getVal和setVal方法,使其识别并适当地处理空值。 - 确定
Expression、Term和Predicate的各种类中哪些需要修改以处理空常量。
8.12. 修改 ProjectScan 类使其成为一个可更新扫描。
8.13. 练习 6.10 要求你为 TableScan 类编写 previous 和 afterLast 方法。
(a) 修改 SimpleDB,使所有扫描都具有这些方法。
(b) 编写一个程序来测试你的代码。请注意,除非你也扩展了其 JDBC 实现,否则你将无法在 SimpleDB 引擎上测试你的更改。参见练习 11.5。
8.14. rename 操作符接受三个参数:一个输入表,表中字段的名称,以及一个新的字段名称。输出表与输入表相同,只是指定字段已被重命名。例如,以下查询将字段 SName 重命名为 StudentName:
rename(STUDENT, SName, StudentName)
编写一个 RenameScan 类来实现此操作符。此课程将在练习 10.13 中需要。
8.15. extend 操作符接受三个参数:一个输入表、一个表达式和一个新的字段名称。输出表与输入表相同,只是它还包含一个新字段,其值由表达式确定。例如,以下查询扩展 STUDENT,添加一个新字段(称为 JuniorYear),计算学生读大三时的年份:
extend(STUDENT, GradYear-1, JuniorYear)
编写一个 ExtendScan 类来实现此操作符。此课程将在练习 10.14 中需要。
8.16. union 关系操作符接受两个参数,它们都是表。其输出表包含那些出现在输入表中的记录。联合查询要求两个底层表具有相同的模式;输出表也将具有该模式。编写一个 UnionScan 类来实现此操作符。此课程将在练习 10.15 中需要。
8.17. semijoin 操作符接受三个参数:两个表和一个谓词。它返回第一个表中在第二个表中有“匹配”记录的记录。例如,以下查询返回至少有一个学生专业的系:
semijoin(DEPT, STUDENT, Did=MajorId)
类似地,antijoin 操作符返回第一个表中没有匹配记录的记录。例如,以下查询返回没有学生专业的系:
antijoin(DEPT, STUDENT, Did=MajorId)
编写 SemijoinScan 和 AntijoinScan 类来实现这些操作符。这些课程将在练习 10.16 中需要。