第 6 章 记录管理 (Record Management)
事务管理器能够在磁盘块上的指定位置读写值。然而,它并不知道块中有哪些值,也不知道这些值可能位于何处。这个责任属于记录管理器 (record manager)。它将文件组织成记录集合,并提供了遍历记录和在其中放置值的方法。本章研究记录管理器提供的功能以及实现该功能所使用的技术。
6.1 设计记录管理器 (Designing a Record Manager)
记录管理器必须解决几个问题,例如:
- 每条记录是否应完全放置在一个块内?
- 块中的所有记录是否都来自同一张表?
- 每个字段是否可以使用预定数量的字节表示?
- 每个字段值应该在记录中的哪个位置?
本节讨论这些问题及其权衡。
6.1.1 跨块记录与非跨块记录 (Spanned Versus Unspanned Records)
假设记录管理器需要将四个 300 字节的记录插入到一个文件中,其中块大小为 1000 字节。三个记录可以很好地放入块的前 900 字节。但是记录管理器应该如何处理第四个记录呢?图 6.1 展示了两种选择。
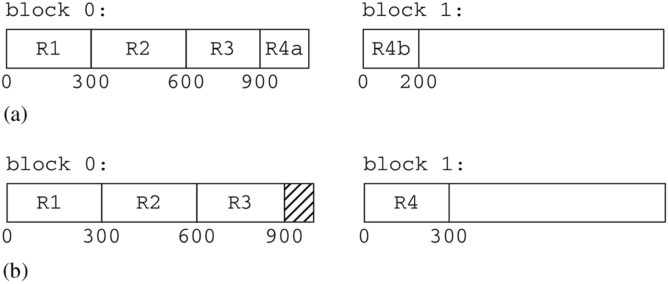
图 6.1 跨块记录与非跨块记录. (a) R4 记录跨越块 0 和块 1, (b)R4 记录完全存储在块 1 中
在图 6.1a 中,记录管理器创建一个跨块记录 (spanned record),即其值跨越两个或更多块的记录。它将记录的前 100 字节存储在现有块中,将记录的后 200 字节存储在新块中。在图 6.1b 中,记录管理器将整个第四个记录存储在一个新块中。
记录管理器必须决定是否创建跨块记录。非跨块记录 (unspanned records) 的缺点是它们浪费磁盘空间。在图 6.1b 中,每个块浪费了 100 字节(或 10%)。更糟糕的情况是,如果每个记录包含 501 字节——那么一个块只能包含 1 条记录,并且近 50% 的空间将被浪费。另一个缺点是,非跨块记录的大小受限于块大小。如果记录可以大于一个块,那么跨块是必要的。
跨块记录的主要缺点是它们增加了记录访问的复杂性 (complexity of record access)。因为跨块记录分布在多个块中,所以读取它需要多次块访问。此外,跨块记录可能需要通过将其读入内存的单独区域来从这些块中重建。
6.1.2 同构文件与非同构文件 (Homogeneous Versus Nonhomogeneous Files)
如果文件中的所有记录都来自同一张表,则该文件是同构的 (homogeneous)。记录管理器必须决定是否允许非同构文件 (nonhomogeneous files)。权衡再次是效率 (efficiency) 与灵活性 (flexibility)。
例如,考虑 图 1.1 中的 STUDENT 和 DEPT 表。同构实现会将所有 STUDENT 记录放在一个文件中,所有 DEPT 记录放在另一个文件中。这种放置使得单表 SQL 查询 (single-table SQL queries) 易于回答——记录管理器只需扫描一个文件的块。然而,多表查询 (multi-table queries) 的效率会降低。考虑一个连接这两个表的查询,例如“查找学生姓名及其主修系”。记录管理器必须在 STUDENT 记录的块和 DEPT 记录的块之间来回搜索(如第 8 章将讨论),寻找匹配的记录。即使查询可以在没有过多搜索的情况下执行(例如,通过第 12 章的索引连接 (index join)),磁盘驱动器仍然必须在读取 STUDENT 和 DEPT 块之间交替时重复寻道。
非同构组织 (nonhomogeneous organization) 会将 STUDENT 和 DEPT 记录存储在同一个文件中,每个学生的记录存储在其主修系记录的附近。图 6.2 描绘了这种组织的前两个块,假设每个块有三条记录。文件由一条 DEPT 记录组成,后面跟着以该系为主修的 STUDENT 记录。这种组织需要更少的块访问来计算连接,因为连接的记录聚簇 (clustered) 在同一个(或附近的)块中。

图 6.2 聚簇、非同构记录
聚簇 (Clustering) 提高了连接聚簇表的查询效率,因为匹配的记录存储在一起。然而,聚簇会导致单表查询效率降低,因为每张表的记录分布在更多的块中。同样,与其他表的连接效率也会降低。因此,聚簇仅在最常用的查询执行由聚簇编码的连接时才有效。
6.1.3 定长字段与变长字段 (Fixed-Length Versus Variable-Length Fields)
表中的每个字段都有一个定义好的类型。基于该类型,记录管理器决定是使用定长 (fixed-length) 还是变长 (variable-length) 表示来实现字段。定长表示使用完全相同的字节数来存储字段的每个值,而变长表示则根据存储的数据值进行扩展和收缩。
大多数类型自然是定长的。例如,整数和浮点数都可以存储为 4 字节的二进制值。事实上,所有数字和日期/时间类型都具有自然的定长表示。Java 类型 String 是需要变长表示的典型示例,因为字符串可以任意长。
变长表示会带来显著的复杂性。例如,考虑一个位于块中间且充满记录的记录,并假设您修改了其一个字段值。如果字段是定长的,那么记录的大小将保持不变,并且可以在原地修改字段。但是,如果字段是变长的,那么记录可能会变大。为了给更大的记录腾出空间,记录管理器可能必须重新排列 (rearrange) 块中记录的位置。事实上,如果修改后的记录变得太大,那么一个或多个记录可能需要移出该块并放置在不同的块中。因此,记录管理器会尽力在可能的情况下使用定长表示。例如,记录管理器可以从字符串字段的三种不同表示中选择:
- 变长表示 (A variable-length representation):记录管理器在记录中为字符串分配所需的精确空间量。
- 定长表示 (A fixed-length representation):记录管理器将字符串存储在记录外部的位置,并在记录中保留对该位置的定长引用。
- 定长表示 (A fixed-length representation):记录管理器在记录中为每个字符串分配相同数量的空间,无论其长度如何。
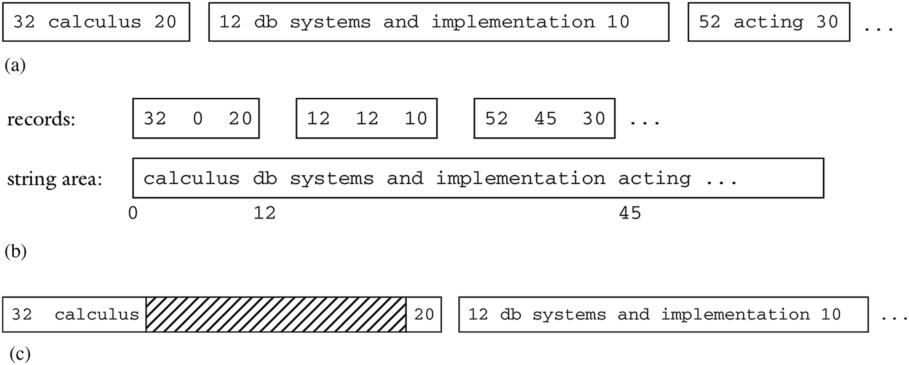
图 6.3 COURSE 记录中 Title 字段的不同表示方法, (a) 为每个字符串分配刚好所需的空间,(b)将字符串存储在单独的位置,(c) 为每个字符串分配相同数量的空间
这些表示如 图 6.3 所示。图 (a) 显示了三个 COURSE 记录,其中 Title 字段使用变长表示实现。这些记录空间效率高,但存在刚刚讨论的问题。
图 (b) 显示了相同的三个记录,但 Title 字符串放置在单独的“字符串区域”中。该区域可以是单独的文件,或者(如果字符串非常大)一个目录,其中每个字符串都存储在自己的文件中。在任何一种情况下,字段都包含对字符串在该区域中位置的引用。这种表示使记录既定长 (fixed-length) 又小巧 (small)。小记录是好的,因为它们可以存储在更少的块中,因此需要更少的块访问。这种表示的缺点是,从记录中检索字符串值需要额外的块访问。
图 (c) 显示了其中两个记录,使用定长 Title 字段实现。这种实现的优点是记录是定长的,并且字符串存储在记录中。然而,缺点是一些记录会比它们需要的更大。如果字符串大小差异很大,那么这种浪费的空间将是显著的,导致文件更大,从而需要更多的块访问。
这些表示方式没有一个明显优于其他。为了帮助记录管理器选择合适的表示方式,标准 SQL 提供了三种不同的字符串数据类型:char、varchar 和 clob。char(n) 类型指定恰好 n 个字符的字符串。varchar(n) 和 clob(n) 类型指定最多 n 个字符的字符串。它们的区别在于 n 的预期大小。在 varchar(n) 中,n 相对较小,例如不超过 4K。另一方面,clob(n) 中 n 的值可以达到千兆字符范围。(CLOB 是“字符大对象”的缩写。)举一个 clob 字段的例子,假设大学数据库在其 SECTION 表中添加了一个 Syllabus 字段,其值将包含每个课程大纲的文本。假设大纲最多可包含 8000 个字符,您可以合理地将该字段定义为 clob(8000)。
char 类型的字段最自然地对应于图 6.3c。由于所有字符串都将具有相同的长度,因此记录内部没有浪费空间,并且定长表示将是最有效的。
varchar(n) 类型的字段最自然地对应于图 6.3a。由于 n 将相对较小,将字符串放置在记录内部不会使记录太大。此外,字符串大小的变化意味着定长表示会浪费空间。因此,变长表示是最好的选择。如果 n 碰巧很小(例如,小于 20),那么记录管理器可能会选择使用第三种表示来实现 varchar 字段。原因是与定长表示的优点相比,浪费的空间将微不足道。
clob 类型的字段对应于图 6.3b,因为该表示最能处理大字符串。通过将大字符串存储在记录外部,记录本身变得更小、更易于管理。
6.1.4 字段在记录中的放置 (Placing Fields in Records)
记录管理器确定其记录的结构。对于定长记录 (fixed-length records),它确定每个字段在记录中的位置。最直接的策略是将字段彼此相邻存储。记录的大小然后变为字段大小的总和,每个字段的偏移量是前一个字段的结尾。
这种将字段紧密打包到记录中的策略适用于基于 Java 的系统(如 SimpleDB 和 Derby),但在其他地方可能会导致问题。问题在于确保值在内存中正确对齐 (aligned)。在大多数计算机中,访问整数的机器代码要求整数存储在 4 的倍数的内存位置中;据说整数对齐在 4 字节边界上 (aligned on a 4-byte boundary)。因此,记录管理器必须确保每个页面中的每个整数都对齐在 4 字节边界上。由于 OS 页面总是对齐在 2 的 N 次幂字节边界上(N 为某个合理大的整数),因此每个页面的第一个字节将正确对齐。因此,记录管理器必须简单地确保每个页面中每个整数的偏移量是 4 的倍数。如果前一个字段的结尾位置不是 4 的倍数,那么记录管理器必须用足够的字节填充 (pad) 它,使其成为 4 的倍数。
例如,考虑 STUDENT 表,它由三个整数字段和一个 varchar(10) 字符串字段组成。整数字段是 4 的倍数,因此它们不需要填充。然而,字符串字段需要 14 个字节(假设第 3.5.2 节的 SimpleDB 表示);因此,它需要填充额外的 2 个字节,以便其后的字段将对齐在 4 的倍数上。
通常,不同的类型可能需要不同数量的填充。例如,双精度浮点数通常对齐在 8 字节边界上,而小整数通常对齐在 2 字节边界上。记录管理器负责确保这些对齐。一个简单的策略是按声明顺序放置字段,填充每个字段以确保下一个字段的正确对齐。一个更巧妙的策略是重新排序 (reorder) 字段,以便所需填充量最少。例如,考虑以下 SQL 表声明:
create table T (A smallint, B double precision, C smallint, D int, E int)
假设字段按给定顺序存储。那么字段 A 需要填充额外的 6 个字节,字段 C 需要填充额外的 2 个字节,导致记录长度为 28 字节;参见 图 6.4a。另一方面,如果字段按顺序 [B, D, A, C, E] 存储,则不需要填充,记录长度仅为 20 字节,如 图 6.4b 所示。
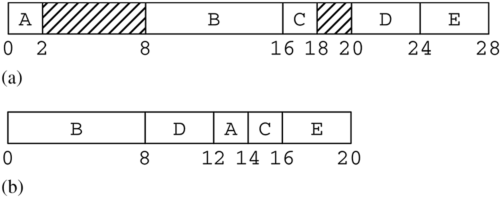
图 6.4 记录中字段的放置以实现对齐 ,(a)需要填充的放置方式图 ,(b) 不需要填充的放置方式
除了填充字段,记录管理器还必须填充 (pad) 每条记录。其思想是每条记录需要以 k 字节边界结束,其中 k 是支持的最大对齐方式,以便页面中的每条记录都与第一条记录具有相同的对齐方式。再次考虑 图 6.4a 的字段放置,其记录长度为 28 字节。假设第一条记录从块的字节 0 开始。那么第二条记录将从块的字节 28 开始,这意味着第二条记录的字段 B 将从块的字节 36 开始,这是错误的对齐方式。每条记录都必须从 8 字节边界开始至关重要。在图 6.4 的示例中,部分 (a) 和部分 (b) 的记录都需要填充额外的 4 个字节。
Java 程序不需要考虑填充,因为它不能直接访问字节数组中的数值。例如,从页面读取整数的 Java 方法是 ByteBuffer.getInt。此方法不调用机器代码指令来获取整数,而是从数组的 4 个指定字节中构造整数本身。此活动不如单个机器代码指令高效,但它避免了对齐问题。
6.2 实现记录文件 (Implementing a File of Records)
前一节讨论了记录管理器必须解决的各种决策。本节将考虑这些决策如何实现。它从最直接的实现开始:一个包含同构 (homogeneous)、非跨块 (unspanned)、定长记录 (fixed-length records) 的文件。然后,它将考虑其他设计决策如何影响此实现。
6.2.1 直接实现 (A Straightforward Implementation)
假设您想创建一个包含同构、非跨块、定长记录的文件。记录非跨块 (unspanned) 的事实意味着您可以将文件视为一个块序列 (sequence of blocks),其中每个块包含自己的记录。记录同构 (homogeneous) 且定长 (fixed-length) 的事实意味着您可以为块内的每条记录分配相同量的空间。换句话说,您可以将每个块视为记录数组 (array of records)。SimpleDB 将这种块称为记录页 (record page)。
记录管理器可以如下实现记录页:它将一个块分成槽 (slots),其中每个槽都足够大,可以容纳一条记录加上一个额外的字节。这个字节的值是一个标志 (flag),表示该槽是空的还是正在使用中;我们假设 0 表示“空”,1 表示“正在使用”。
例如,假设块大小为 400 字节,记录大小为 26 字节;那么每个槽长 27 字节,块可以容纳 14 个槽,并浪费 22 字节的空间。图 6.5 描绘了这种情况。此图显示了 14 个槽中的 4 个;槽 0 和 13 当前包含记录,而槽 1 和 2 是空的。

图 6.5 一个记录页,包含 14 条 26 字节记录的空间
记录管理器需要能够插入、删除和修改记录页中的记录。为此,它使用关于记录的以下信息:
- 槽的大小 (The size of a slot)
- 记录每个字段的名称、类型、长度和偏移量 (The name, type, length, and offset of each field of a record)
这些值构成了记录的布局 (layout)。例如,考虑图 2.4 中定义的 STUDENT 表。一个 STUDENT 记录包含三个整数加上一个十字符的 varchar 字段。假设 SimpleDB 的存储策略,每个整数需要 4 字节,一个十字符字符串需要 14 字节。我们还假设不需要填充,varchar 字段通过为最大可能的字符串分配固定空间来实现,并且空/使用中标志在每个槽的开头占用一个字节。图 6.6 给出了此表的结果布局。
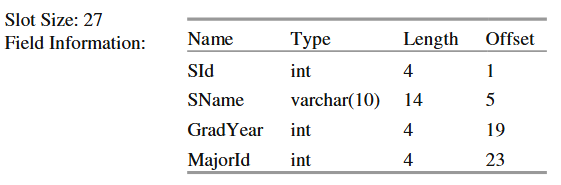
图 6.6 STUDENT 表的布局
给定一个布局,记录管理器可以确定页面中每个值的位置。槽 k 中的记录从位置 RL * k + Offset(F) 开始,其中 RL 是记录长度。该记录的空/使用中标志位于位置 RL * k,其字段 F 的值位于位置 RL * k + Offset(F)。
记录管理器可以非常容易地处理插入、删除、修改和检索操作:
- 插入新记录 (To insert a new record):记录管理器检查每个槽的空/使用中标志,直到找到一个 0。然后它将标志设置为 1 并返回该槽的位置。如果所有标志值都是 1,则该块已满,无法插入。
- 删除记录 (To delete a record):记录管理器只需将其空/使用中标志设置为 0。
- 修改记录的字段值 (To modify a field value of a record)(或初始化新记录的字段):记录管理器确定该字段的位置并将值写入该位置。
- 检索页面中的记录 (To retrieve the records in the page):记录管理器检查每个槽的空/使用中标志。每次找到 1 时,它就知道该槽包含一条现有记录。
记录管理器还需要一种方法来标识记录页中的记录。当记录是定长时,最直接的记录标识符是其槽号 (slot number)。
6.2.2 实现变长字段 (Implementing Variable-Length Fields)
定长字段的实现非常直接。本节将考虑引入变长字段如何影响该实现。
一个问题是记录中字段的偏移量不再固定 (field offsets in a record are no longer fixed)。特别是,所有在变长字段之后的字段的偏移量将因记录而异。确定这些字段偏移量的唯一方法是读取前一个字段并查看它在哪里结束。如果记录中的第一个字段是变长字段,那么为了确定第 n 个字段的偏移量,有必要读取记录的前 n-1 个字段。因此,记录管理器通常将定长字段放在每条记录的开头 (fixed-length fields at the beginning of each record),以便可以通过预先计算的偏移量访问它们。变长字段则放在记录的末尾。第一个变长字段将具有固定偏移量,但其余的则不会。
另一个问题是修改字段值会导致记录长度改变 (modifying a field value can cause a record’s length to change)。如果新值更大,则必须移动 (shifted) 修改值右侧的块内容以腾出空间。在极端情况下,移动的记录将溢出 (spill out of) 块;这种情况必须通过分配一个溢出块 (overflow block) 来处理。溢出块是从称为溢出区 (overflow area) 的区域分配的新块。任何溢出原始块的记录都会从该块中删除并添加到溢出块中。如果发生许多此类修改,则可能需要由几个溢出块组成的链。每个块将包含对链中下一个溢出块的引用。从概念上讲,原始块和溢出块形成一个单一的(大)记录页。
例如,考虑 COURSE 表,并假设课程标题保存为变长字符串 (variable-length strings)。图 6.7a 描绘了一个包含该表前三条记录的块。(Title 字段已移到记录末尾,因为其他字段是定长的。)图 6.7b 描绘了将标题“DbSys”修改为“Database Systems Implementation”的结果。假设块大小为 80 字节,第三条记录不再适合该块,因此它被放置在溢出块 (overflow block) 中。原始块包含对该溢出块的引用。
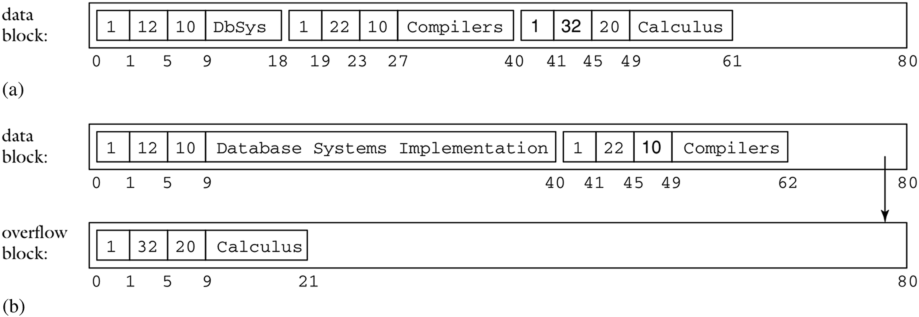
图 6.7 使用溢出块实现变长记录。(a) 原始块,(b) 修改课程 12 标题后的结果

图 6.8 使用 ID 表实现变长记录。(a) 原始块,(b) 删除记录 1 的直接方法,(c) 使用 ID 表删除记录 1
第三个问题是关于将槽号 (slot number) 作为记录标识符 (record identifier) 的使用。不再可能像定长记录那样将槽号乘以槽大小。找到具有给定 ID 的记录开头唯一的方法是从块的开头开始读取记录 (read the records starting from the beginning of the block)。
将槽号作为记录标识符还会使记录插入复杂化。图 6.8 说明了这个问题。
图 (a) 描绘了一个包含前三条 COURSE 记录的块,与图 6.7a 相同。删除课程 22 的记录会将标志设置为 0(表示“空”)并保持记录不变,如图 (b) 所示。此空间现在可用于插入。然而,只有当其 Title 字段包含九个或更少字符时,才能将记录插入到该空间中。通常,即使存在由较小已删除记录留下的许多空白空间,新记录也可能不适合该块。该块被称为碎片化 (fragmented)。
减少这种碎片化的一种方法是移动剩余的记录 (shift the remaining records),使它们都集中在块的一端。然而,这样做会改变移动记录的槽号,这不幸地改变了它们的 ID。
解决这个问题的方法是使用ID 表 (ID table) 将记录的槽号与其在页面中的位置分离 (dissociate)。ID 表是一个存储在页面开头的整数数组。数组中的每个槽都表示一个记录 ID (record id)。数组中的值是具有该 ID 的记录的位置;值为 0 表示当前没有记录具有该 ID。图 6.8c 描绘了与图 6.8b 相同的数据,但带有一个 ID 表。ID 表包含三个条目:其中两个指向块中偏移量 63 和 43 处的记录,另一个为空。位置 63 处的记录 ID 为 0,位置 43 处的记录 ID 为 2。目前没有 ID 为 1 的记录。
ID 表提供了一个间接级别 (level of indirection),允许记录管理器在块内移动记录。如果记录移动,其在 ID 表中的条目会相应调整;如果记录被删除,其条目将设置为 0。当插入新记录时,记录管理器会在数组中找到一个可用的条目,并将其分配为新记录的 ID。通过这种方式,ID 表允许变长记录在块内移动,同时为每条记录提供一个固定标识符 (fixed identifier)。
ID 表随着块中记录数量的增加而扩展。数组的大小必然是开放式 (open-ended) 的,因为一个块可以容纳数量不等的变长记录。通常,ID 表放在块的一端,记录放在另一端,它们相互生长 (grow toward each other)。这种情况可以在图 6.8c 中看到,其中块中的第一条记录位于其最右端。ID 表使得空/使用中标志 (empty/inuse flags) 不再必要。如果 ID 表的条目指向一条记录,则该记录正在使用中。空记录的 ID 为 0(实际上甚至不存在)。ID 表还使记录管理器能够快速找到块中的每条记录。要移动到具有特定 ID 的记录,记录管理器只需使用存储在 ID 表该条目中的位置;要移动到下一条记录,记录管理器扫描 ID 表直到找到下一个非零条目。
6.2.3 实现跨块记录 (Implementing Spanned Records)
本节将考虑如何实现跨块记录 (spanned records)。当记录非跨块 (unspanned) 时,每个块中的第一条记录始终从相同的位置开始。对于跨块记录,这种情况不再成立。因此,记录管理器必须在每个块的开头存储一个整数,以保存第一条记录的偏移量 (offset)。

图 6.9 实现跨块记录
例如,考虑图 6.9。块 0 中的第一个整数是 4,表示第一条记录 R1 从偏移量 4 开始(即紧跟在该整数之后)。记录 R2 跨越块 0 和块 1,因此块 1 中的第一条记录是 R3,它从偏移量 60 开始。记录 R3 继续通过块 2 进入块 3。记录 R4 是块 3 中的第一条记录,从偏移量 30 开始。请注意,块 2 的第一个整数是 0,表示该块中没有记录开始。
记录管理器可以选择以两种不同的方式拆分跨块记录。第一种方式是尽可能地填充块,在块边界处拆分;剩余的字节放置在文件的下一个块(或多个块)中。第二种方式是逐值写入记录;当页面满时,写入继续在新页面上。第一种方式的优点是它绝对不浪费空间 (wastes absolutely no space),但缺点是将值拆分到多个块中 (splitting a value across blocks)。要访问拆分的值,记录管理器必须通过连接来自两个块的字节来重建 (reconstruct) 该值。
6.2.4 实现非同构记录 (Implementing Nonhomogeneous Records)
如果记录管理器支持非同构记录 (nonhomogeneous records),那么它还需要支持变长记录 (variable-length records),因为来自不同表的记录大小不必相同。在块中包含非同构记录有两个问题:
- 记录管理器需要知道块中每种记录的布局 (layout)。
- 给定一条记录,记录管理器需要知道它来自哪个表。
记录管理器可以通过维护一个布局数组 (array of layouts) 来解决第一个问题,每个可能的表对应一个布局。记录管理器可以通过在每条记录的开头添加一个额外的值 (value) 来解决第二个问题;这个值有时称为标签值 (tag value),它是布局数组的索引 (index),指定该记录所属的表。
例如,再次考虑图 6.2,它描绘了来自 DEPT 和 STUDENT 表的非同构块。记录管理器将维护一个包含这两个表布局信息的数组;我们假设 DEPT 信息在数组的索引 0 中,STUDENT 信息在索引 1 中。那么来自 DEPT 的每条记录的标签值将是 0,而每条 STUDENT 记录的标签值将是 1。
记录管理器的行为不需要太多改变。当记录管理器访问一条记录时,它会根据标签值确定要使用哪个表信息。然后它可以使用该表来读取或写入任何字段,与同构情况相同。
SimpleDB 中的日志记录 (log records) 是非同构记录的一个例子。每个日志记录的第一个值是一个整数,表示日志记录的类型。恢复管理器使用该值来确定如何读取记录的其余部分。
6.3 SimpleDB 记录页面 (SimpleDB Record Pages)
接下来的两节将探讨 SimpleDB 的记录管理器,它实现了 6.2.1 节介绍的基本记录管理器。本节涵盖了记录页面的实现 (implementation of record pages),而下一节将介绍如何实现记录页面文件 (file of record pages)。本章的一些期末练习会要求您修改它以处理其他设计决策。
6.3.1 管理记录信息 (Managing Record Information)
SimpleDB 的记录管理器使用 Schema 和 Layout 类来管理记录的信息。它们的 API 如 图 6.10 所示。
图 6.10 SimpleDB 记录信息的 API
Schema 类 (Schema Class)
public Schema(): 构造函数,创建一个新的Schema对象。public void addField(String fldname, int type, int length): 添加一个字段,指定字段名、类型和长度。public void addIntField(String fldname): 便捷方法,添加一个整数字段。public void addStringField(String fldname, int length): 便捷方法,添加一个字符串字段,指定最大长度。public void add(String fldname, Schema sch): 从另一个Schema对象复制指定字段的信息。public void addAll(Schema sch): 从另一个Schema对象复制所有字段的信息。public List<String> fields(): 获取所有字段名称的列表。public boolean hasField(String fldname): 检查模式中是否存在指定字段。public int type(String fldname): 获取指定字段的类型。public int length(String fldname): 获取指定字段的长度(对字符串而言是最大字符数)。
Layout 类 (Layout Class)
public Layout(Schema schema): 构造函数,根据给定的Schema计算并创建物理布局。public Layout(Schema schema, Map<String,Integer> offsets, int slotSize): 构造函数,使用已计算的偏移量和槽大小创建布局(用于加载现有表)。public Schema schema(): 获取关联的Schema对象。public int offset(String fldname): 获取指定字段在槽内的字节偏移量。public int slotSize(): 获取每个记录槽的总字节大小。
一个 Schema 对象 保存着记录的模式 (schema),即每个字段的名称、类型以及每个字符串字段的长度。这些信息对应于用户在创建表时会指定的内容,并且不包含任何物理存储信息。例如,字符串的长度是指允许的最大字符数,而不是其在字节中的实际大小。
Schema 可以被认为是 [字段名, 类型, 长度] 形式的三元组列表。Schema 类包含五个方法来向此列表添加三元组。addField 方法显式地添加一个三元组。addIntField、addStringField、add 和 addAll 都是便捷方法;前两个方法计算三元组,后两个方法从现有模式中复制三元组。该类还具有访问器方法 (accessor methods),用于检索字段名集合,确定指定字段是否在集合中,以及检索指定字段的类型和长度。
Layout 类 则额外包含了记录的物理信息 (physical information)。它计算字段和槽的大小,以及字段在槽内的偏移量。该类有两个构造函数,对应于创建 Layout 对象的两种原因。第一个构造函数在创建表时调用;它根据给定的模式计算布局信息。第二个构造函数在表创建后调用;客户端只需提供先前计算好的值。
图 6.11 中的代码片段演示了这两个类的用法。代码的第一部分创建了一个包含 COURSE 表三个字段的模式,然后从该模式创建了一个 Layout 对象。代码的第二部分打印了每个字段的名称和偏移量。
图 6.11 指定 COURSE 记录的结构 (Specifying the structure of COURSE records)
Schema sch = new Schema(); // 创建一个新的 Schema 对象
sch.addIntField("cid"); // 添加一个名为 "cid" 的整数字段
sch.addStringField("title", 20); // 添加一个名为 "title" 的字符串字段,最大长度为 20
sch.addIntField("deptid"); // 添加一个名为 "deptid" 的整数字段
Layout layout = new Layout(sch); // 根据 Schema 创建 Layout 对象,计算物理布局
// 遍历布局中的所有字段,并打印它们的名称和偏移量
for (String fldname : layout.schema().fields()) {
int offset = layout.offset(fldname); // 获取字段的字节偏移量
System.out.println(fldname + " has offset " + offset); // 打印结果
}
6.3.2 实现 Schema 和 Layout (Implementing the Schema and Layout)
Schema 类 的代码非常直接,如 图 6.12 所示。在内部,该类将三元组存储在以字段名作为键的 Map 中。与字段名关联的对象属于私有内部类 FieldInfo,它封装了字段的长度和类型。
图 6.12 SimpleDB Schema 类的代码 (The code for SimpleDB class Schema)
public class Schema {
private List<String> fields = new ArrayList<>(); // 存储字段名的列表,保持顺序
private Map<String,FieldInfo> info = new HashMap<>(); // 存储字段信息(FieldInfo对象),键为字段名
// 显式添加字段的方法
public void addField(String fldname, int type, int length) {
fields.add(fldname); // 将字段名添加到列表中
info.put(fldname, new FieldInfo(type, length)); // 将字段信息存储到Map中
}
// 添加整数字段的便捷方法 (类型为 INTEGER,长度为 0,因为整数长度固定)
public void addIntField(String fldname) {
addField(fldname, INTEGER, 0);
}
// 添加字符串字段的便捷方法 (类型为 VARCHAR,指定长度)
public void addStringField(String fldname, int length) {
addField(fldname, VARCHAR, length);
}
// 从另一个 Schema 复制指定字段
public void add(String fldname, Schema sch) {
int type = sch.type(fldname);
int length = sch.length(fldname);
addField(fldname, type, length);
}
// 从另一个 Schema 复制所有字段
public void addAll(Schema sch) {
for (String fldname : sch.fields())
add(fldname, sch);
}
// 获取所有字段名
public List<String> fields() {
return fields;
}
// 检查是否包含某个字段
public boolean hasField(String fldname) {
return fields.contains(fldname);
}
// 获取指定字段的类型
public int type(String fldname) {
return info.get(fldname).type;
}
// 获取指定字段的长度
public int length(String fldname) {
return info.get(fldname).length;
}
// 私有内部类,封装字段的类型和长度
class FieldInfo {
int type, length;
public FieldInfo(int type, int length) {
this.type = type;
this.length = length;
}
}
}
类型由 JDBC 类 Types 中定义的常量 INTEGER 和 VARCHAR 表示。字段的长度仅对字符串字段有意义;addIntField 方法为整数赋予长度值 0,但此值不相关,因为它永远不会被访问。
Layout 类 的代码如 图 6.13 所示。第一个构造函数按照它们在 Schema 中出现的顺序定位字段。它以字节为单位确定每个字段的长度,将槽大小 (slot size) 计算为字段长度的总和,并为整数大小的空/使用中标志额外添加四个字节。它将标志分配在槽的偏移量 0 处,并将每个字段的偏移量分配为前一个字段结束的位置(即没有填充 (no padding))。
图 6.13 SimpleDB Layout 类的代码 (The code for the SimpleDB class Layout)
public class Layout {
private Schema schema; // 关联的 Schema 对象
private Map<String,Integer> offsets; // 存储字段名到其在槽中偏移量的映射
private int slotsize; // 每个记录槽的总大小(字节)
// 构造函数:根据 Schema 计算布局
public Layout(Schema schema) {
this.schema = schema;
offsets = new HashMap<>();
// 从 Integer.BYTES (4字节) 处开始计算字段偏移量,因为前 4 字节用于空/使用中标志
int pos = Integer.BYTES;
for (String fldname : schema.fields()) {
offsets.put(fldname, pos); // 记录当前字段的偏移量
pos += lengthInBytes(fldname); // 增加位置,为下一个字段做准备
}
slotsize = pos; // 槽大小等于所有字段长度加上标志位的总和
}
// 构造函数:使用预先计算好的偏移量和槽大小(用于加载现有表)
public Layout(Schema schema, Map<String,Integer> offsets, int slotsize) {
this.schema = schema;
this.offsets = offsets;
this.slotsize = slotsize;
}
// 获取关联的 Schema
public Schema schema() {
return schema;
}
// 获取指定字段的偏移量
public int offset(String fldname) {
return offsets.get(fldname);
}
// 获取槽的大小
public int slotSize() {
return slotsize;
}
// 私有辅助方法:计算字段在字节中的实际长度
private int lengthInBytes(String fldname) {
int fldtype = schema.type(fldname);
if (fldtype == INTEGER)
return Integer.BYTES; // 整数字段固定为 Integer.BYTES 字节 (通常是 4)
else // fldtype == VARCHAR
// 字符串字段的长度由 Page.maxLength 计算,基于其最大字符数
return Page.maxLength(schema.length(fldname));
}
}
6.3.3 管理页面中的记录 (Managing the Records in a Page)
RecordPage 类 管理页面中的记录。它的 API 如 图 6.14 所示。
图 6.14 SimpleDB 记录页的 API (The API for SimpleDB record pages)
RecordPage 类 (RecordPage Class)
public RecordPage(Transaction tx, BlockId blk, Layout layout): 构造函数,用于管理特定块 (blk) 上具有给定layout的记录,所有操作都在一个事务 (tx) 内完成。public BlockId block(): 返回该页面所属块的BlockId。public int getInt(int slot, String fldname): 从指定槽位、指定字段获取一个整数值。public String getString(int slot, String fldname): 从指定槽位、指定字段获取一个字符串值。public void setInt(int slot, String fldname, int val): 在指定槽位、指定字段设置一个整数值。public void setString(int slot, String fldname, String val): 在指定槽位、指定字段设置一个字符串值。public void format(): 格式化页面,将所有记录槽设置为默认值(标志为空,整数为 0,字符串为空)。public void delete(int slot): 删除指定槽位的记录(将其标志设为空)。public int nextAfter(int slot): 在指定槽位之后查找下一个已使用的槽位。如果找不到,返回负值。public int insertAfter(int slot): 在指定槽位之后查找下一个空槽位。如果找到,将其标志设为“已使用”并返回槽号;否则返回负值。
get/set 方法访问指定记录中指定字段的值。delete 方法将记录的标志设置为 EMPTY。format 方法为页面中所有记录槽提供默认值。它将每个空/使用中标志设置为 EMPTY,所有整数设置为 0,所有字符串设置为 ""。
RecordTest 类 演示了 RecordPage 方法的使用;其代码如 图 6.15 所示。它定义了一个包含两个字段的记录模式:一个整数字段 A 和一个字符串字段 B。然后它为新块创建一个 RecordPage 对象并对其进行格式化。for 循环使用 insertAfter 方法用随机值记录填充页面。(每个 A 值是 0 到 49 之间的随机数,B 值是该数字的字符串版本。)两个 while 循环使用 nextAfter 方法搜索页面。第一个循环删除选定的记录,第二个循环打印剩余记录的内容。
图 6.15 测试 RecordPage 类 (Testing the RecordPage class)
public class RecordTest {
public static void main(String[] args) throws Exception {
// 初始化SimpleDB,指定数据库名称、块大小和缓冲区数量
SimpleDB db = new SimpleDB("recordtest", 400, 8);
Transaction tx = db.newTx(); // 开始一个新的事务
// 定义记录的模式 (Schema)
Schema sch = new Schema();
sch.addIntField("A"); // 添加一个名为"A"的整数字段
sch.addStringField("B", 9); // 添加一个名为"B"的字符串字段,最大长度为9字符
Layout layout = new Layout(sch); // 根据Schema创建布局
// 打印字段名称和它们的偏移量
for (String fldname : layout.schema().fields()) {
int offset = layout.offset(fldname);
System.out.println(fldname + " has offset " + offset);
}
// 将一个新块附加到"testfile"并将其钉住(pin)在缓冲区中
BlockId blk = tx.append("testfile");
tx.pin(blk);
// 创建一个RecordPage对象来管理这个块中的记录
RecordPage rp = new RecordPage(tx, blk, layout);
rp.format(); // 格式化页面,将所有槽位标记为"空"并初始化字段
System.out.println("Filling the page with random records.");
// 从-1(表示从开头)开始插入记录,直到页面满
int slot = rp.insertAfter(-1);
while (slot >= 0) {
int n = (int) Math.round(Math.random() * 50); // 生成0到50之间的随机整数
rp.setInt(slot, "A", n); // 设置字段"A"的值
rp.setString(slot, "B", "rec"+n); // 设置字段"B"的值(字符串形式)
System.out.println("inserting into slot " + slot + ": {"+ n + ", " + "rec"+n + "}");
slot = rp.insertAfter(slot); // 获取下一个可用的槽位
}
System.out.println("Deleted these records with A-values < 25.");
int count = 0;
// 从-1(表示从开头)开始查找已使用的槽位
slot = rp.nextAfter(-1);
while (slot >= 0) {
int a = rp.getInt(slot, "A"); // 获取字段"A"的值
String b = rp.getString(slot, "B"); // 获取字段"B"的值
if (a < 25) { // 如果A的值小于25
count++;
System.out.println("slot " + slot + ": {"+ a + ", " + b + "}");
rp.delete(slot); // 删除该记录
}
slot = rp.nextAfter(slot); // 获取下一个已使用的槽位
}
System.out.println(count + " values under 25 were deleted.\n");
System.out.println("Here are the remaining records.");
// 再次从-1(表示从开头)开始查找已使用的槽位,打印剩余记录
slot = rp.nextAfter(-1);
while (slot >= 0) {
int a = rp.getInt(slot, "A");
String b = rp.getString(slot, "B");
System.out.println("slot " + slot + ": {"+ a + ", " + b + "}");
slot = rp.nextAfter(slot);
}
tx.unpin(blk); // 解除块的钉住
tx.commit(); // 提交事务
}
}
6.3.4 实现记录页 (Implementing Record Pages)
SimpleDB 实现了 图 6.5 中所示的槽页结构 (slotted-page structure)。唯一的区别是空/使用中标志被实现为 4 字节整数而不是单个字节(原因是 SimpleDB 不支持字节大小的值)。RecordPage 类的代码如 图 6.16 所示。
图 6.16 SimpleDB RecordPage 类的代码 (The code for the SimpleDB class RecordPage)
public class RecordPage {
public static final int EMPTY = 0, USED = 1; // 定义槽状态常量:空和已使用
private Transaction tx; // 事务对象
private BlockId blk; // 块ID
private Layout layout; // 记录布局
// 构造函数:初始化RecordPage对象,并钉住(pin)其关联的块
public RecordPage(Transaction tx, BlockId blk, Layout layout) {
this.tx = tx;
this.blk = blk;
this.layout = layout;
tx.pin(blk);
}
// 获取指定槽位、指定字段的整数值
public int getInt(int slot, String fldname) {
int fldpos = offset(slot) + layout.offset(fldname); // 计算字段的绝对字节位置
return tx.getInt(blk, fldpos); // 从块中读取整数
}
// 获取指定槽位、指定字段的字符串值
public String getString(int slot, String fldname) {
int fldpos = offset(slot) + layout.offset(fldname); // 计算字段的绝对字节位置
return tx.getString(blk, fldpos); // 从块中读取字符串
}
// 设置指定槽位、指定字段的整数值
public void setInt(int slot, String fldname, int val) {
int fldpos = offset(slot) + layout.offset(fldname); // 计算字段的绝对字节位置
tx.setInt(blk, fldpos, val, true); // 向块中写入整数,并记录日志
}
// 设置指定槽位、指定字段的字符串值
public void setString(int slot, String fldname, String val) {
int fldpos = offset(slot) + layout.offset(fldname); // 计算字段的绝对字节位置
tx.setString(blk, fldpos, val, true); // 向块中写入字符串,并记录日志
}
// 删除指定槽位的记录(通过设置其标志为空)
public void delete(int slot) {
setFlag(slot, EMPTY);
}
// 格式化页面:将所有槽位标记为“空”,并初始化字段为默认值
public void format() {
int slot = 0;
while (isValidSlot(slot)) { // 遍历所有可能的槽位
tx.setInt(blk, offset(slot), EMPTY, false); // 设置标志为空,不记录日志(格式化是初始操作)
Schema sch = layout.schema();
for (String fldname : sch.fields()) {
int fldpos = offset(slot) + layout.offset(fldname);
if (sch.type(fldname) == INTEGER)
tx.setInt(blk, fldpos, 0, false); // 初始化整数为0,不记录日志
else
tx.setString(blk, fldpos, "", false); // 初始化字符串为空串,不记录日志
}
slot++;
}
}
// 在指定槽位之后查找下一个已使用的槽位
public int nextAfter(int slot) {
return searchAfter(slot, USED);
}
// 在指定槽位之后查找下一个空槽位,如果找到则标记为已使用
public int insertAfter(int slot) {
int newslot = searchAfter(slot, EMPTY);
if (newslot >= 0) // 如果找到了空槽位
setFlag(newslot, USED); // 将其标志设置为“已使用”
return newslot;
}
// 获取此RecordPage关联的块ID
public BlockId block() {
return blk;
}
// 私有辅助方法
// 设置指定槽位的标志
private void setFlag(int slot, int flag) {
tx.setInt(blk, offset(slot), flag, true); // 设置标志并记录日志
}
// 在指定槽位之后搜索具有特定标志(USED或EMPTY)的槽位
private int searchAfter(int slot, int flag) {
slot++; // 从下一个槽位开始搜索
while (isValidSlot(slot)) { // 只要槽位有效
if (tx.getInt(blk, offset(slot)) == flag) // 检查槽位的标志是否匹配
return slot; // 找到匹配的槽位,返回其槽号
slot++; // 否则,移动到下一个槽位
}
return -1; // 没有找到匹配的槽位
}
// 检查指定槽位是否有效(即是否在块的范围内)
private boolean isValidSlot(int slot) {
// 槽位有效条件:该槽位紧邻的下一个槽位的起始位置不超出块大小
return offset(slot+1) <= tx.blockSize();
}
// 计算指定槽位的起始字节偏移量
private int offset(int slot) {
return slot * layout.slotSize(); // 槽号乘以槽大小
}
}
私有方法 offset 使用槽大小来计算记录槽的起始位置。get/set 方法通过将字段的偏移量(从 Layout 获取)添加到记录的偏移量来计算其指定字段的位置。nextAfter 和 insertAfter 方法分别调用私有方法 searchAfter 来查找具有指定标志(USED 或 EMPTY)的槽。searchAfter 方法会重复递增指定的槽号,直到找到具有指定标志的槽或用完槽。delete 方法将指定槽的标志设置为 EMPTY,而 insertAfter 将找到的槽的标志设置为 USED。
好的,我将再次调整格式,确保英文原文标题不包含编号,而中文翻译部分保留原有的章节编号。代码部分将保持中文注释。
6.4 SimpleDB 表扫描 (SimpleDB Table Scans)
一个记录页管理一个记录块。本节将探讨表扫描,它可以在文件的多个块中存储任意数量的记录。
6.4.1 表扫描 (Table Scans)
TableScan 类管理表中的记录。其 API 如 Fig. 6.17 所示。一个 TableScan 对象会跟踪一个当前记录,其方法可以改变当前记录并访问其内容。beforeFirst 方法将当前记录定位到文件中的第一条记录之前,而 next 方法将当前记录定位到文件中的下一条记录。如果当前块中没有更多记录,那么 next 将读取文件中的后续块,直到找到另一条记录。如果无法找到更多记录,则调用 next 将返回 false。
TableScan
public class TableScan {
// 构造函数,初始化TableScan对象
public TableScan(Transaction tx, String tblname, Layout layout) { /* ... */ }
// 关闭TableScan
public void close() { /* ... */ }
// 检查字段是否存在
public boolean hasField(String fldname) { /* ... */ }
// methods that establish the current record (建立当前记录的方法)
// 将当前记录定位到文件中的第一条记录之前
public void beforeFirst() { /* ... */ }
// 将当前记录定位到文件中的下一条记录,如果成功则返回true
public boolean next() { /* ... */ }
// 将当前记录定位到指定的记录标识符(RID)
public void moveToRid(RID r) { /* ... */ }
// 插入一条新记录
public void insert() { /* ... */ }
// methods that access the current record (访问当前记录的方法)
// 获取当前记录中指定字段的整数值
public int getInt(String fldname) { /* ... */ }
// 获取当前记录中指定字段的字符串值
public String getString(String fldname) { /* ... */ }
// 设置当前记录中指定字段的整数值
public void setInt(String fldname, int val) { /* ... */ }
// 设置当前记录中指定字段的字符串值
public void setString(String fldname, String val) { /* ... */ }
// 返回当前记录的记录标识符(RID)
public RID currentRid() { /* ... */ }
// 删除当前记录
public void delete() { /* ... */ }
}
RID
public class RID {
// 构造函数,根据块号和槽位创建RID对象
public RID(int blknum, int slot) { /* ... */ }
// 获取记录所在的块号
public int blockNumber() { /* ... */ }
// 获取记录在块中的槽位
public int slot() { /* ... */ }
}
Fig. 6.17 The API for SimpleDB table scans (Fig. 6.17 SimpleDB 表扫描的 API)
get/set 和 delete 方法应用于当前记录。insert 方法在文件的某个位置插入一条新记录,从当前记录所在的块开始。与 RecordPage 的插入方法不同,此插入方法总是成功;如果它无法在文件中现有块中找到插入记录的位置,它会向文件中追加一个新块并将记录插入其中。
文件中的每条记录都可以通过一对值来标识:它在文件中的块号以及在块中的槽位。这两个值被称为记录标识符 (rid)。RID 类实现了这些记录标识符。其类构造函数保存这两个值;访问器方法 blockNumber 和 slot 则检索它们。
TableScan 类包含两个与 rid 交互的方法。moveToRid 方法将当前记录定位到指定的 rid,而 currentRid 方法返回当前记录的 rid。
TableScan 类提供了一个与您目前所见的其它类显著不同的抽象层次。也就是说,Page、Buffer、Transaction 和 RecordPage 的方法都适用于特定的块。而 TableScan 类则向其客户端隐藏了块结构。通常,客户端不会知道(或关心)当前正在访问哪个块。
public class TableScanTest {
public static void main(String[] args) throws Exception {
// 创建SimpleDB实例,数据库名为"tabletest",缓冲区大小400,块大小8
SimpleDB db = new SimpleDB("tabletest", 400, 8);
// 开始一个新事务
Transaction tx = db.newTx();
// 创建一个Schema(模式)对象
Schema sch = new Schema();
// 向模式中添加一个名为"A"的整型字段
sch.addIntField("A");
// 向模式中添加一个名为"B"的字符串字段,最大长度为9
sch.addStringField("B", 9);
// 根据模式创建一个Layout(布局)对象
Layout layout = new Layout(sch);
// 遍历布局中所有字段的名称,并打印其偏移量
for (String fldname : layout.schema().fields()) {
int offset = layout.offset(fldname);
System.out.println(fldname + " has offset " + offset);
}
// 创建一个TableScan对象,用于表"T"
TableScan ts = new TableScan(tx, "T", layout);
System.out.println("Filling the table with 50 random records."); // 填充表,共50条随机记录。
// 将当前记录定位到文件中的第一条记录之前
ts.beforeFirst();
// 循环插入50条随机记录
for (int i=0; i<50; i++) {
// 插入一条新记录
ts.insert();
// 生成一个0到50之间的随机整数
int n = (int) Math.round(Math.random() * 50);
// 设置字段"A"的值
ts.setInt("A", n);
// 设置字段"B"的值
ts.setString("B", "rec"+n);
// 打印插入的记录信息,包括记录的RID和内容
System.out.println("inserting into slot " + ts.currentRid() + ": {" // 插入到槽位
+ n + ", " + "rec"+n + "}");
}
System.out.println("Deleting records with A-values < 25."); // 删除 A 值小于 25 的记录。
int count = 0;
// 将当前记录定位到文件中的第一条记录之前
ts.beforeFirst();
// 遍历所有记录
while (ts.next()) {
// 获取字段"A"的值
int a = ts.getInt("A");
// 获取字段"B"的值
String b = ts.getString("B");
// 如果A的值小于25,则删除该记录
if (a < 25) {
count++;
System.out.println("slot " + ts.currentRid() + ": {"+ a + ", " + b + "}"); // 槽位
// 删除当前记录
ts.delete();
}
}
System.out.println(count + " values under 10 were deleted.\n"); // 个小于 10 的值被删除了。
System.out.println("Here are the remaining records."); // 以下是剩余记录。
// 将当前记录定位到文件中的第一条记录之前
ts.beforeFirst();
// 遍历并打印所有剩余的记录
while (ts.next()) {
int a = ts.getInt("A");
String b = ts.getString("B");
System.out.println("slot " + ts.currentRid() +": {" + a + ", " + b + "}"); // 槽位
}
// 关闭TableScan
ts.close();
// 提交事务
tx.commit();
}
}
Fig. 6.18 Testing the table scan (Fig. 6.18 测试表扫描)
Fig. 6.18 中的 TableScanTest 类展示了表扫描的使用。该代码类似于 RecordTest,不同之处在于它向文件中插入了 50 条记录。对 ts.insert 的调用将分配必要的块来容纳这些记录。在本例中,将分配三个块(每个块 18 条记录)。然而,代码并不知道正在发生这些事情。如果您多次运行此代码,您会发现文件又插入了 50 条记录,并且它们填充了之前删除记录所遗弃的槽位。
6.4.2 实现表扫描 (Implementing Table Scans)
TableScan 类的代码如 Fig. 6.19 所示。一个 TableScan 对象持有其当前块的记录页。get/set/delete 方法只是简单地调用记录页的相应方法。当当前块改变时,会调用私有方法 moveToBlock;该方法关闭当前记录页,并为指定块打开另一个记录页,将其定位在第一个槽位之前。next 方法的算法如下:
- 移动到当前记录页的下一条记录。
- 如果该页中没有更多记录,则移动到文件的下一个块并获取其下一条记录。
- 继续直到找到下一条记录或到达文件末尾。 文件中的多个块可能为空(参见练习 6.2),因此调用
next可能需要循环遍历多个块。
insert 方法尝试在当前记录之后开始插入一条新记录。如果当前块已满,则它移动到下一个块并继续,直到找到一个空槽位。如果所有块都已满,则它会向文件中追加一个新块并将记录插入其中。
TableScan 实现了 UpdateScan 接口(并通过扩展也实现了 Scan 接口)。这些接口是查询执行的核心,将在第 8 章中讨论。getVal 和 setVal 方法也将在第 8 章中讨论。它们获取和设置 Constant 类型的对象。Constant 是值类型(如 int 或 String)的抽象,它使得表达查询变得更容易,而无需知道给定字段的类型。
RID 对象简单地由两个整数组合而成:块号和槽位号。因此,RID 类的代码非常直观,如 Fig. 6.20 所示。
public class TableScan implements UpdateScan {
private Transaction tx; // 事务对象
private Layout layout; // 布局对象
private RecordPage rp; // 当前记录页
private String filename; // 文件名
private int currentslot; // 当前槽位
// 构造函数
public TableScan(Transaction tx, String tblname, Layout layout) {
this.tx = tx;
this.layout = layout;
filename = tblname + ".tbl"; // 构建表文件名
// 如果文件大小为0(即文件为空),则移动到一个新块
if (tx.size(filename) == 0)
moveToNewBlock();
else
// 否则移动到文件的第一个块(块号为0)
moveToBlock(0);
}
// Methods that implement Scan (实现Scan接口的方法)
// 关闭TableScan,解除对当前记录页的pin
public void close() {
if (rp != null)
tx.unpin(rp.block());
}
// 将当前记录定位到文件中的第一条记录之前
public void beforeFirst() {
moveToBlock(0); // 移动到第一个块
}
// 移动到下一条记录
public boolean next() {
// 在当前记录页中查找下一个槽位
currentslot = rp.nextAfter(currentslot);
// 如果当前页没有更多记录 (currentslot < 0)
while (currentslot < 0) {
// 如果已到达文件的最后一个块,则返回false,表示没有更多记录
if (atLastBlock())
return false;
// 否则,移动到文件的下一个块
moveToBlock(rp.block().number() + 1);
// 在新块中查找下一个槽位
currentslot = rp.nextAfter(currentslot);
}
return true; // 找到下一条记录,返回true
}
// 获取当前记录中指定字段的整数值
public int getInt(String fldname) {
return rp.getInt(currentslot, fldname);
}
// 获取当前记录中指定字段的字符串值
public String getString(String fldname) {
return rp.getString(currentslot, fldname);
}
// 获取当前记录中指定字段的Constant类型值
public Constant getVal(String fldname) {
// 根据字段类型返回IntConstant或StringConstant
if (layout.schema().type(fldname) == INTEGER)
return new IntConstant(getInt(fldname));
else
return new StringConstant(getString(fldname));
}
// 检查模式中是否包含指定字段
public boolean hasField(String fldname) {
return layout.schema().hasField(fldname);
}
// Methods that implement UpdateScan (实现UpdateScan接口的方法)
// 设置当前记录中指定字段的整数值
public void setInt(String fldname, int val) {
rp.setInt(currentslot, fldname, val);
}
// 设置当前记录中指定字段的字符串值
public void setString(String fldname, String val) {
rp.setString(currentslot, fldname, val);
}
// 设置当前记录中指定字段的Constant类型值
public void setVal(String fldname, Constant val) {
// 根据字段类型将Constant值转换为Java基本类型并设置
if (layout.schema().type(fldname) == INTEGER)
setInt(fldname, (Integer) val.asJavaVal());
else
setString(fldname, (String) val.asJavaVal());
}
// 插入一条新记录
public void insert() {
// 尝试在当前槽位之后插入新记录
currentslot = rp.insertAfter(currentslot);
// 如果当前块已满 (currentslot < 0)
while (currentslot < 0) {
// 如果已到达文件的最后一个块,则追加一个新块
if (atLastBlock())
moveToNewBlock();
else
// 否则,移动到文件的下一个块
moveToBlock(rp.block().number() + 1);
// 在新块中尝试插入新记录
currentslot = rp.insertAfter(currentslot);
}
}
// 删除当前记录
public void delete() {
rp.delete(currentslot);
}
// 移动到指定的RID(记录标识符)
public void moveToRid(RID rid) {
close(); // 关闭当前记录页
BlockId blk = new BlockId(filename, rid.blockNumber()); // 根据RID的块号创建BlockId
rp = new RecordPage(tx, blk, layout); // 为该块创建RecordPage
currentslot = rid.slot(); // 设置当前槽位
}
// 获取当前记录的RID
public RID getRid() {
return new RID(rp.block().number(), currentslot);
}
// Private auxiliary methods (私有辅助方法)
// 移动到指定的块号
private void moveToBlock(int blknum) {
close(); // 关闭当前记录页
BlockId blk = new BlockId(filename, blknum); // 创建目标块的BlockId
rp = new RecordPage(tx, blk, layout); // 为目标块创建RecordPage
currentslot = -1; // 将当前槽位重置为-1(在第一个槽位之前)
}
// 移动到一个新块(追加新块到文件末尾)
private void moveToNewBlock() {
close(); // 关闭当前记录页
BlockId blk = tx.append(filename); // 向文件追加一个新块并获取其BlockId
rp = new RecordPage(tx, blk, layout); // 为新块创建RecordPage
rp.format(); // 格式化新块
currentslot = -1; // 将当前槽位重置为-1
}
// 检查是否已到达文件的最后一个块
private boolean atLastBlock() {
return rp.block().number() == tx.size(filename) - 1;
}
}
Fig. 6.19 The code for the SimpleDB class TableScan ( SimpleDB 类 TableScan 的代码)
public class RID {
private int blknum; // 块号
private int slot; // 槽位
// 构造函数
public RID(int blknum, int slot) {
this.blknum = blknum;
this.slot = slot;
}
// 获取块号
public int blockNumber() {
return blknum;
}
// 获取槽位
public int slot() {
return slot;
}
// 重写equals方法,用于比较两个RID对象是否相等
public boolean equals(Object obj) {
RID r = (RID) obj; // 将传入对象转换为RID类型
return blknum == r.blknum && slot == r.slot; // 比较块号和槽位是否都相等
}
// 重写toString方法,返回RID的字符串表示形式
public String toString() {
return "[" + blknum + ", " + slot + "]";
}
}
Fig. 6.20 The code for the SimpleDB class RID (Fig. 6.20 SimpleDB 类 RID 的代码)
6.5 章总结 (Chapter Summary)
-
记录管理器
是数据库系统中负责在文件中存储记录的部分。它有三个基本职责:
- 在记录内部放置字段。
- 在块内部放置记录。
- 提供对文件中记录的访问。
在设计记录管理器时,有几个问题必须解决。
- 一个问题是是否支持变长字段。定长记录可以轻松实现,因为字段可以在原地更新。更新变长字段可能导致记录溢出块并被放置到溢出块中。
- SQL 有三种不同的字符串类型:
char、varchar和clob。char类型最自然地使用定长表示实现。varchar类型最自然地使用变长表示实现。clob类型最自然地使用存储字符串到辅助文件中的定长表示实现。
- 变长记录的一种常见实现技术是使用 ID 表。表中的每个条目指向页面中的一条记录。记录可以通过仅更改其在 ID 表中的条目而在页面中移动。
- 第二个问题是是否创建跨块记录。跨块记录很有用,因为它们不浪费空间并允许存储大记录,但实现起来更复杂。
- 第三个问题是是否允许文件中存在非同构记录。非同构记录允许相关记录在同一页面上聚簇。聚簇可以带来非常高效的连接操作,但往往会使其他查询变得更昂贵。记录管理器可以通过在每条记录的开头存储一个标签字段来实现非同构记录;该标签表示记录所属的表。
- 第四个问题是如何确定记录中每个字段的偏移量。记录管理器可能需要填充字段,以便它们对齐到适当的字节边界。定长记录中的字段在每条记录中具有相同的偏移量。可能需要搜索变长记录以找到其字段的开头。
6.6 建议阅读 (Suggested Reading)
本章中的思想和技术从关系数据库的最初就已存在。Stonebraker et al. (1976) 的第 3.3 节描述了第一个版本 INGRES 所采用的方法;该方法使用了第 6.2.2 节中描述的 ID 表的变体。Astrahan et al. (1976) 的第 3 节描述了早期 System R 数据库系统(后来成为 IBM 的 DB2 产品)的页面结构,该系统非同构地存储记录。这两篇文章都讨论了广泛的实现思想,非常值得通读。Gray and Reuter (1993) 第 14 章更详细地讨论了这些技术,并提供了示例记录管理器的基于 C 语言的实现。将每条记录连续存储在一个页面中的策略不一定是最好的。
Ailamaki et al. (2002) 的文章主张将页面上的记录分解开,并将每个字段的值放在一起。尽管这种记录组织方式不会改变记录管理器执行的磁盘访问次数,但它显著提高了 CPU 的性能,因为其数据缓存得到了更有效的利用。Stonebraker et al. (2005) 的文章更进一步,提出表应该按字段值组织,即每个字段的所有记录值都应该存储在一起。该文章展示了基于字段的存储如何比基于记录的存储更紧凑,这可以带来更高效的查询。Carey et al. (1986) 描述了一种针对超大记录的实现策略。
Ailamaki, A., DeWitt, D., & Hill, M. (2002). Data page layouts for relational databases on deep memory hierarchies. VLDB Journal, 11(3), 198–215.
Astrahan, M., Blasgen, M., Chamberlin, D., Eswaren, K., Gray, J., Griffiths, P.,King, W., Lorie, R., McJones, P., Mehl, J., Putzolu, G., Traiger, I., Wade, B., & Watson, V. (1976). System R: Relational approach to database management.
ACM Transactions on Database Systems, 1(2), 97–137.
Carey, M., DeWitt, D., Richardson, J., & Shekita, E. (1986). Object and file management in the EXODUS extendable database system. In Proceedings of the VLDB Conference (pp. 91–100).
Gray, J., & Reuter, A. (1993). Transaction processing: concepts and techniques. San Mateo, CA: Morgan Kaufman.
Stonebraker, M., Abadi, D., Batkin, A., Chen, X., Cherniack, M., Ferreira, M., Lau,E., Lin, A., Madden, S., O’Neil, E., O’Neil, P., Rasin, A., Tran, N., & Zdonik,S. (2005). C-Store: A column-oriented DBMS. In Proceedings of the VLDB Conference (pp. 553–564).
Stonebraker, M., Kreps, P., Wong, E., & Held, G. (1976). The design and imple- mentation of INGRES. ACM Transactions on Database Systems, 1(3), 189–222.
6.7 练习 (Exercises)
概念问题 (Conceptual Problems)
6.1. 假设块大小为 400 字节,并且记录不能跨块。计算 SimpleDB 记录页中可容纳的最大记录数以及在以下槽位大小下页面中浪费的空间量:10 字节、20 字节、50 字节和 100 字节。
6.2. 解释表的文件如何包含没有记录的块。
6.3. 考虑大学数据库中的每个表(除了 STUDENT)。
(a) 给出该表的布局,如 Fig. 6.6 所示。(您可以使用演示客户端文件中的 varchar 声明,或者假设所有字符串字段都定义为 varchar(20)。)
(b) 使用 Fig. 1.1 中的记录,绘制每个表的记录页面图(如 Fig. 6.5 所示)。如 Fig. 6.5 所示,假设空/满标志是一个字节长。还假设字符串字段是定长实现。
(c) 完成 (b) 部分,但假设字符串字段是变长实现。使用 Fig. 6.8c 作为模型。
(d) 修改 (b) 和 (c) 部分的图片,以显示其第二条记录被删除后页面的状态。
6.4. 处理超大字符串的另一种方法是将其不存储在数据库中。相反,您可以将字符串放在操作系统文件中,并将文件名称存储在数据库中。这种策略将消除对 clob 类型的需求。
给出几个理由说明为什么这种策略不是特别好。
6.5. 假设您想将一条记录插入到一个包含溢出块的块中,如 Fig. 6.7b 所示。将记录保存在溢出块中是个好主意吗?解释。
6.6. 这是实现变长记录的另一种方法。每个块有两个区域:一系列定长槽位(如 SimpleDB 中)和存储变长值的地方。记录存储在槽位中。其定长值与记录一起存储,其变长值存储在值区域。记录将包含值所在块的偏移量。例如,Fig. 6.8a 中的记录可以这样存储:
(a) 解释当变长值被修改时应该发生什么。您需要溢出块吗?如果需要,它应该是什么样子?
(b) 将此存储策略与 ID 表进行比较。解释各自的比较优势。
(c) 您更喜欢哪种实现策略?为什么?
6.7. 使用一个字节表示每个空/使用中标志浪费了空间,因为只需要一个位。另一种实现策略是在块的开头,用位数组存储每个槽位的空/使用中位。这个位数组可以实现为一个或多个 4 字节整数。
(a) 将此位数组与 Fig. 6.8c 中的 ID 表进行比较。
(b) 假设块大小为 4K,记录至少为 15 字节。存储位数组需要多少个整数?
(c) 描述一个查找空槽位以插入新记录的算法。
(d) 描述一个查找块中下一个非空记录的算法。
编程问题 (Programming Problems)
6.8. 修改 RecordPage 类,使其块不在构造函数中被 pin,而是在每个 get/set 方法的开头被 pin。类似地,块在每个 get/set 方法的末尾被 unpin,从而消除了对 close 方法的需求。您认为这比 SimpleDB 的实现更好吗?解释。
6.9. 修改记录管理器,使 varchar 字段具有变长实现。
6.10. SimpleDB 只知道如何向前读取文件。
(a) 修改 TableScan 和 RecordPage 类以支持 previous 方法,以及 afterLast 方法,该方法将当前记录定位到文件(或页面)中最后一条记录之后。
(b) 修改 TableScanTest 程序以反向打印其记录。
6.11. 修改记录管理器,使记录跨块。
6.12. 修改 Layout 类,填充字符串字段,使其大小始终是 4 的倍数。
6.13. 修改 SimpleDB 记录管理器以处理空字段值。由于使用特定的整数或字符串值来表示空是不合理的,您应该使用标志来指定哪些值为空。具体来说,假设一条记录包含 N 个字段。那么您可以为每条记录存储 N 个额外的位,使得第 i 个位的值为 1 当且仅当第 i 个字段的值为空。假设 N<32,空/使用中整数可以用于此目的。该整数的第 0 位表示空/使用中,如前所述。但现在其他位包含空值信息。您应该对代码进行以下修改:
-
修改
Layout,使其具有一个bitLocation(fldname)方法,该方法返回字段空信息位在标志中的位置。 -
修改
RecordPage和TableScan,使其具有两个额外的公共方法:一个void方法setNull(fldname),它在标志的适当位中存储 1;以及一个boolean方法isNull(fldname),如果当前记录指定字段的空位为 1,则返回true。 -
修改
RecordPage的format方法,以明确将新记录的字段设置为非空。 -
修改
setString和setInt方法,将指定字段设置为非空。
6.14. 假设 setString 被调用时,传入的字符串长度超过了模式中指定的长度。
(a) 解释可能出现哪些问题以及何时会被检测到。
(b) 修复 SimpleDB 代码,以便检测并适当地处理该错误。