第 4 章 内存管理 (Chapter 4 Memory Management)
本章将研究数据库引擎的两个组件:日志管理器 (log manager) 和缓冲区管理器 (buffer manager)。每个组件都负责特定的文件:日志管理器负责日志文件,缓冲区管理器负责数据文件。
这两个组件都面临着如何高效管理磁盘块与主内存之间读写的问题。数据库内容通常远大于主内存,因此这些组件可能需要将块在内存中移入移出 (shuttle blocks in and out of memory)。本章将检查它们的内存需求以及它们使用的内存管理算法。日志管理器仅支持对日志文件的顺序访问 (sequential access),并采用一个简单、最优的内存管理算法。另一方面,缓冲区管理器必须支持对用户文件的任意访问 (arbitrary access),这是一个更困难的挑战。
4.1 数据库内存管理的两个原则 (Two Principles of Database Memory Management)
回想一下,数据库引擎读取磁盘值的唯一方法是将其所在的块读入内存中的一个页面,而写入磁盘值的唯一方法是将修改后的页面写回其块。数据库引擎在磁盘和内存之间移动数据时遵循两个重要原则:最小化磁盘访问,以及不依赖虚拟内存。
原则 1: 最小化磁盘访问 (Principle 1: Minimize Disk Accesses)
考虑一个应用程序,它从磁盘读取数据,搜索数据,执行各种计算,进行一些更改,然后将数据写回。您如何估计这需要多长时间?回想一下,RAM 操作比闪存快 1000 多倍,比磁盘快 100,000 倍。这意味着在大多数实际情况中,从磁盘读/写块所需的时间至少与在 RAM 中处理块所需的时间一样长。因此,数据库引擎可以做的最重要的事情就是最小化块访问。
最小化块访问的一种方法是避免多次访问同一个磁盘块。这种问题在计算的许多领域都会出现,并且有一个标准解决方案,称为缓存 (caching)。例如,CPU 有一个本地硬件缓存,用于存储以前执行的指令;如果下一条指令在缓存中,CPU 就无需从 RAM 加载它。另一个例子是,浏览器会保留以前访问过的网页的缓存;如果用户请求一个恰好在缓存中的页面(例如,通过点击浏览器的“后退”按钮),浏览器就可以避免从网络检索它。
数据库引擎使用内存页来缓存磁盘块。通过跟踪哪些页面包含哪些块的内容,引擎可能能够通过使用现有页面来满足客户端请求,从而避免磁盘读取。同样,引擎只在必要时将页面写入磁盘,希望通过一次磁盘写入完成对页面的多次更改。
最小化磁盘访问的需求非常重要,它渗透到数据库引擎的整个实现中。例如,引擎使用的检索算法之所以被选择,正是因为它们节俭地访问磁盘。当一个 SQL 查询有几种可能的检索策略时,查询规划器会选择它认为需要最少磁盘访问次数的策略。
原则 2: 不依赖虚拟内存 (Principle 2: Don’t Rely on Virtual Memory)
现代操作系统支持虚拟内存 (virtual memory)。操作系统给每个进程一个错觉,认为它拥有大量内存来存储其代码和数据。进程可以在其虚拟内存空间中任意分配对象;操作系统将每个虚拟页面映射到物理内存中的一个实际页面。操作系统支持的虚拟内存空间通常远大于计算机的物理内存。由于并非所有虚拟页面都能放入物理内存,因此操作系统必须将其中一些存储在磁盘上。当进程访问不在内存中的虚拟页面时,就会发生页面交换 (page swap)。操作系统选择一个物理页面,将该页面的内容写入磁盘(如果它已被修改),然后将虚拟页面的保存内容从磁盘读取到该页面。
数据库引擎管理磁盘块最直接的方法是为每个块分配自己的虚拟页面。例如,它可以为每个文件保留一个页面数组,每个文件的每个块都有一个槽位。这些数组会很大,但它们会适应虚拟内存。当数据库系统访问这些页面时,虚拟内存机制会根据需要将它们在磁盘和物理内存之间交换。这是一种简单、易于实现的策略。不幸的是,它有一个严重的问题,那就是操作系统而非数据库引擎控制页面何时写入磁盘。由此产生了两个问题。
第一个问题是,操作系统的页面交换策略会损害数据库引擎在系统崩溃后恢复的能力。原因(正如您将在第 5 章中看到的那样)是修改过的页面会有一些相关的日志记录,这些日志记录必须在页面之前写入磁盘。(否则,日志记录将无法用于帮助数据库在系统崩溃后恢复。)由于操作系统不知道日志,它可能会在不写入其日志记录的情况下交换出修改过的页面,从而破坏恢复机制。
第二个问题是,操作系统不知道哪些页面当前正在使用,哪些页面数据库引擎不再关心。操作系统可以做出有根据的猜测,例如选择交换最近最少访问的页面。但是,如果操作系统猜测不正确,它将交换出再次需要的页面,导致两次不必要的磁盘访问。另一方面,数据库引擎对需要哪些页面有更好的了解,可以做出更明智的猜测。
因此,数据库引擎必须管理自己的页面。它通过分配相对少量的、它知道能够放入物理内存的页面来做到这一点;这些页面被称为数据库的缓冲区池 (buffer pool)。引擎会跟踪哪些页面可用于交换。当一个块需要读入一个页面时,数据库引擎(而不是操作系统)从缓冲区池中选择一个可用页面,如果需要,将其内容(及其日志记录)写入磁盘,然后才读入指定的块。
4.2 日志信息管理 (Managing Log Information)
每当用户更改数据库时,数据库引擎都必须跟踪该更改,以备需要撤销。描述更改的值保存在日志记录 (log record) 中,日志记录存储在日志文件 (log file) 中。新的日志记录会追加到日志的末尾。
日志管理器 (log manager) 是数据库引擎中负责将日志记录写入日志文件的组件。日志管理器不理解日志记录的内容——这项职责属于第 5 章的恢复管理器。相反,日志管理器将日志视为一个不断增长的日志记录序列。
本节将研究日志管理器在将日志记录写入日志文件时如何管理内存。考虑图 4.1 所示的算法,这是将记录追加到日志的最直接方法。
1. 分配一个内存页面。
2. 将日志文件的最后一个块读入该页面。
3a. 如果有空间,将日志记录放在页面上其他记录之后,并将页面写回磁盘。
3b. 如果没有空间,则分配一个新的空页面,将日志记录放入该页面,
并将该页面追加到日志文件末尾的新块中。
图 4.1 将新记录追加到日志的简单(但低效)算法
此算法要求每个追加的日志记录进行一次磁盘读取和一次磁盘写入。它简单但效率非常低。图 4.2 说明了日志管理器在算法的第 3a 步进行到一半时的操作。日志文件包含三个块,这些块包含八条记录,标记为 r1 到 r8。日志记录的大小可能不同,这就是为什么块 0 中可以容纳四条记录,而块 1 中只能容纳三条记录的原因。块 2 尚未满,只包含一条记录。内存页面包含块 2 的内容。除了记录 r8,一条新的日志记录(记录 r9)刚刚被放入页面中。
现在假设日志管理器通过将页面写回文件的块 2 来完成算法。当日志管理器最终被要求向文件添加另一条日志记录时,它将执行算法的第 1 步和第 2 步,并将块 2 读入一个页面。但请注意,此磁盘读取是完全不必要的,因为现有的日志页面已经包含块 2 的内容!因此,算法的第 1 步和第 2 步是不必要的。日志管理器只需要永久分配一个页面来包含最后一个日志块的内容。 结果是,所有的磁盘读取都被消除了。
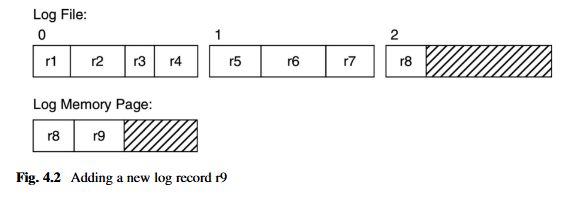
减少磁盘写入也是可能的。在上述算法中,日志管理器每次向页面添加新记录时,都会将其页面写入磁盘。查看图 4.2,您可以看到无需立即将记录 r9 写入磁盘。只要页面有空间,每个新日志记录都可以简单地添加到页面中。当页面变满时,日志管理器可以将页面写入磁盘,清除其内容,然后重新开始。这种新算法将导致每个日志块恰好一次磁盘写入,这显然是最佳的。
此算法有一个小问题:由于日志管理器无法控制的情况,日志页面可能需要在其变满之前写入磁盘。问题在于,缓冲区管理器不能将修改过的数据页面写入磁盘,除非该页面关联的日志记录也已写入磁盘。 如果这些日志记录中的任何一个恰好在日志页面中但尚未在磁盘上,则日志管理器必须将其页面写入磁盘,无论页面是否已满。这个问题将在第 5 章中解决。
图 4.3 给出了最终的日志管理算法。此算法在两个地方将内存页面写入磁盘:当需要强制将日志记录写入磁盘时,以及当页面已满时。因此,一个内存页面可能会被写入同一个日志块多次。但由于这些磁盘写入是绝对必要的且无法避免的,您可以得出结论,该算法是最佳的。
1. 永久分配一个内存页面来保存日志文件的最后一个块的内容。称此页面为 P。
2. 当提交新的日志记录时:
a) 如果 P 中没有空间,则:
将 P 写入磁盘并清除其内容。
b) 将新日志记录追加到 P 中。
3. 当数据库系统请求将特定日志记录写入磁盘时:
a) 确定该日志记录是否在 P 中。
b) 如果是,则将 P 写入磁盘。
图 4.3 最佳日志管理算法
4.3 SimpleDB 日志管理器 (The SimpleDB Log Manager)
本节将探讨 SimpleDB 数据库系统的日志管理器。第 4.3.1 节将演示日志管理器的使用。第 4.3.2 节将分析其实现。
4.3.1 日志管理器的 API (The API for the Log Manager)
SimpleDB 日志管理器的实现位于 simpledb.log 包中。此包公开了 LogMgr 类,其 API 如 图 4.4 所示。
public class LogMgr {
// 构造函数:初始化 LogMgr 对象
public LogMgr(FileMgr fm, String logfile);
// 将记录追加到日志并返回其 LSN
public int append(byte[] rec);
// 确保指定的 LSN 及之前的记录已写入磁盘
public void flush(int lsn);
// 返回一个迭代器,用于反向读取日志记录
public Iterator<byte[]> iterator();
}
图 4.4 SimpleDB 日志管理器的 API
数据库引擎有一个 LogMgr 对象,它在系统启动时创建。构造函数的参数是对文件管理器的引用和日志文件的名称。
append 方法将记录添加到日志并返回一个整数。就日志管理器而言,日志记录是一个任意大小的字节数组;它将数组保存在日志文件中,但不知道其内容表示什么。唯一的限制是数组必须适合一个页面。append 的返回值标识新的日志记录;此标识符称为其日志序列号 (log sequence number,或 LSN)。
将记录追加到日志并不保证记录会写入磁盘;相反,日志管理器会选择何时将日志记录写入磁盘,如 图 4.3 的算法所示。客户端可以通过调用 flush 方法将特定日志记录强制写入磁盘。flush 的参数是日志记录的 LSN;该方法确保此日志记录(以及所有先前的日志记录)已写入磁盘。
客户端调用 iterator 方法来读取日志中的记录;此方法返回日志记录的 Java 迭代器。每次调用迭代器的 next 方法都将返回一个表示日志中下一条记录的字节数组。迭代器方法返回的记录是逆序的,从最新的记录开始,然后向后遍历日志文件。记录以这种顺序返回是因为恢复管理器希望以这种方式查看它们。
图 4.5 中的 LogTest 类提供了一个如何使用日志管理器 API 的示例。该代码创建了 70 条日志记录,每条记录包含一个字符串和一个整数。整数是记录号 N,字符串是值“recordN”。代码在创建前 35 条记录后打印一次记录,然后在创建所有 70 条记录后再打印一次。
public class LogTest {
private static LogMgr lm;
public static void main(String[] args) {
SimpleDB db = new SimpleDB("logtest", 400, 8); // 初始化 SimpleDB 实例
lm = db.logMgr(); // 获取日志管理器实例
createRecords(1, 35); // 创建 1 到 35 号记录
printLogRecords("日志文件现在有这些记录:"); // 打印当前日志记录
createRecords(36, 70); // 创建 36 到 70 号记录
lm.flush(65); // 强制 LSN 为 65 的记录及其之前的记录写入磁盘
printLogRecords("日志文件现在有这些记录:"); // 再次打印日志记录
}
private static void printLogRecords(String msg) {
System.out.println(msg);
Iterator<byte[]> iter = lm.iterator(); // 获取日志迭代器
while (iter.hasNext()) {
byte[] rec = iter.next(); // 获取下一条日志记录(字节数组)
Page p = new Page(rec); // 将字节数组包装成 Page 对象
String s = p.getString(0); // 从 Page 中读取字符串
int npos = Page.maxLength(s.length()); // 计算整数的位置
int val = p.getInt(npos); // 从 Page 中读取整数
System.out.println("[" + s + ", " + val + "]"); // 打印记录内容
}
System.out.println();
}
private static void createRecords(int start, int end) {
System.out.print("正在创建记录: ");
for (int i = start; i <= end; i++) {
byte[] rec = createLogRecord("record" + i, i + 100); // 创建日志记录的字节数组
int lsn = lm.append(rec); // 将记录追加到日志
System.out.print(lsn + " "); // 打印返回的 LSN
}
System.out.println();
}
// 辅助方法:根据字符串和整数创建日志记录的字节数组
private static byte[] createLogRecord(String s, int n) {
int npos = Page.maxLength(s.length()); // 计算整数存储位置
byte[] b = new byte[npos + Integer.BYTES]; // 创建足够大的字节数组
Page p = new Page(b); // 包装成 Page
p.setString(0, s); // 写入字符串
p.setInt(npos, n); // 写入整数
return b;
}
}
图 4.5 测试日志管理器
如果您运行代码,您会发现第一次调用 printLogRecords 后只打印了 20 条记录。原因是这些记录填满了第一个日志块,并在创建第 21 条日志记录时被刷新到磁盘。其他 15 条日志记录保留在内存中的日志页面中,没有被刷新。第二次调用 createRecords 创建了记录 36 到 70。调用 flush 会告诉日志管理器确保记录 65 在磁盘上。但由于记录 66-70 与记录 65 位于同一页面中,它们也写入了磁盘。因此,第二次调用 printLogRecords 将逆序打印所有 70 条记录。
请注意 createLogRecord 方法如何分配一个字节数组作为日志记录。它创建了一个 Page 对象来包装该数组,以便它可以使用页面的 setInt 和 setString 方法将字符串和整数放置在日志记录中适当的偏移量处。然后代码返回字节数组。类似地,printLogRecords 方法创建一个 Page 对象来包装日志记录,以便它可以从记录中提取字符串和整数。
4.3.2 实现日志管理器 (Implementing the Log Manager)
LogMgr 的代码如 图 4.6 所示。其构造函数使用提供的字符串作为日志文件的名称。如果日志文件为空,构造函数会向其追加一个新的空块。构造函数还会分配一个单独的页面(称为 logpage),并将其初始化为包含文件中最后一个日志块的内容。
public class LogMgr {
private FileMgr fm; // 文件管理器实例
private String logfile; // 日志文件名称
private Page logpage; // 内存中的日志页面
private BlockId currentblk; // 当前日志块的 ID
private int latestLSN = 0; // 最新分配的 LSN
private int lastSavedLSN = 0; // 最后保存到磁盘的 LSN
public LogMgr(FileMgr fm, String logfile) {
this.fm = fm;
this.logfile = logfile;
byte[] b = new byte[fm.blockSize()]; // 创建一个字节数组,大小为文件管理器定义的块大小
logpage = new Page(b); // 将字节数组包装成 Page 对象
int logsize = fm.length(logfile); // 获取日志文件大小
if (logsize == 0) // 如果日志文件为空
currentblk = appendNewBlock(); // 追加一个新的空块
else {
currentblk = new BlockId(logfile, logsize - 1); // 设置当前块为日志文件最后一个块
fm.read(currentblk, logpage); // 将最后一个日志块的内容读入 logpage
}
}
// 刷新日志到指定 LSN
public void flush(int lsn) {
if (lsn >= lastSavedLSN) // 如果请求的 LSN 大于或等于最后保存的 LSN
flush(); // 执行实际的刷新操作
}
// 获取日志记录迭代器
public Iterator<byte[]> iterator() {
flush(); // 在创建迭代器前确保所有日志记录已写入磁盘
return new LogIterator(fm, currentblk); // 返回新的 LogIterator
}
// 将日志记录追加到日志
public synchronized int append(byte[] logrec) {
int boundary = logpage.getInt(0); // 获取当前页面的边界(已写入记录的起始偏移量)
int recsize = logrec.length; // 新记录的大小
int bytesneeded = recsize + Integer.BYTES; // 新记录所需的字节数(包括长度前缀)
if (boundary - bytesneeded < Integer.BYTES) { // 如果新记录不适合当前页面
flush(); // 将当前页面内容写入磁盘
currentblk = appendNewBlock(); // 追加一个新块,并将其内容读入 logpage
boundary = logpage.getInt(0); // 更新边界
}
int recpos = boundary - bytesneeded; // 计算新记录的起始位置
logpage.setBytes(recpos, logrec); // 将新记录写入页面
logpage.setInt(0, recpos); // 更新页面头部的边界
latestLSN += 1; // 增加最新 LSN
return latestLSN; // 返回新记录的 LSN
}
// 追加一个新块到日志文件
private BlockId appendNewBlock() {
BlockId blk = fm.append(logfile); // 在日志文件末尾追加一个新块
logpage.setInt(0, fm.blockSize()); // 将页面边界设置为块大小(表示整个页面为空)
fm.write(blk, logpage); // 将(空的)页面写入新块
return blk;
}
// 执行实际的刷新操作,将 logpage 内容写入磁盘
private void flush() {
fm.write(currentblk, logpage); // 将 logpage 内容写入当前块
lastSavedLSN = latestLSN; // 更新最后保存到磁盘的 LSN
}
}
图 4.6 SimpleDB 类 LogMgr 的代码
回想一下,日志序列号 (LSN) 标识一个日志记录。append 方法使用变量 latestLSN 从 1 开始顺序分配 LSN。日志管理器跟踪下一个可用的 LSN 和最近写入磁盘的日志记录的 LSN。flush 方法将最新 LSN 与指定 LSN 进行比较。如果指定 LSN 较小,则所需的日志记录肯定已经写入磁盘;否则,logpage 被写入磁盘,并且 latestLSN 成为最近写入的 LSN。
append 方法计算日志记录的大小以确定它是否适合当前页面。如果不适合,它将当前页面写入磁盘并调用 appendNewBlock 以清除页面并将现在空的页面追加到日志文件。此策略与图 4.3 的算法略有不同;即,日志管理器通过向其追加一个空页面来扩展日志文件,而不是通过追加一个已满的页面来扩展文件。此策略实现起来更简单,因为它允许 flush 假定该块已经存在于磁盘上。
请注意,append 方法将日志记录从右到左放置在页面中。变量 boundary 包含最近添加的记录的偏移量。此策略使日志迭代器能够通过从左到右读取来逆序读取记录。boundary 值写入页面的前四个字节,以便迭代器知道记录从何处开始。
iterator 方法刷新日志(以确保整个日志都在磁盘上),然后返回一个 LogIterator 对象。LogIterator 类是一个包私有类,它实现了迭代器;其代码如 图 4.7 所示。LogIterator 对象分配一个页面来保存日志块的内容。构造函数将迭代器定位到日志中最后一个块的第一条记录(请记住,这是最后一条日志记录写入的位置)。next 方法移动到页面中的下一条记录;当没有更多记录时,它会读取前一个块进入页面并返回其第一条记录。
class LogIterator implements Iterator<byte[]> {
private FileMgr fm; // 文件管理器实例
private BlockId blk; // 当前日志块的 ID
private Page p; // 内存中的页面,用于读取日志块
private int currentpos; // 当前在页面中读取的位置
private int boundary; // 当前页面中已写入记录的起始偏移量
public LogIterator(FileMgr fm, BlockId blk) {
this.fm = fm;
this.blk = blk;
byte[] b = new byte[fm.blockSize()]; // 创建一个字节数组,大小为文件管理器定义的块大小
p = new Page(b); // 将字节数组包装成 Page 对象
moveToBlock(blk); // 移动到指定的日志块并读取其内容
}
// 检查是否还有更多日志记录可供读取
public boolean hasNext() {
// 如果当前位置小于块大小(页面中还有未读取的数据)或者当前块号大于 0(前面还有块)
return currentpos < fm.blockSize() || blk.number() > 0;
}
// 获取下一条日志记录
public byte[] next() {
if (currentpos == fm.blockSize()) { // 如果当前页面已读完
blk = new BlockId(blk.fileName(), blk.number() - 1); // 移动到前一个块
moveToBlock(blk); // 读取前一个块的内容
}
byte[] rec = p.getBytes(currentpos); // 从当前位置读取字节数组(日志记录)
currentpos += Integer.BYTES + rec.length; // 更新当前位置,跳过已读记录的长度和其自身内容
return rec; // 返回日志记录
}
// 移动到指定块并读取其内容
private void moveToBlock(BlockId blk) {
fm.read(blk, p); // 将指定块的内容读入页面 p
boundary = p.getInt(0); // 获取页面头部的边界(日志记录的起始位置)
currentpos = boundary; // 将当前读取位置设置为边界
}
}
图 4.7 SimpleDB 类 LogIterator 的代码
hasNext 方法在页面中没有更多记录且没有更多前一个块时返回 false。
4.4 用户数据管理 (Managing User Data)
日志记录以有限且明确的方式使用。因此,日志管理器可以对其内存使用进行微调;特别是,它能够通过单个专用页面最优地完成其工作。同样,每个 LogIterator 对象也只需要一个页面。
另一方面,JDBC 应用程序访问其数据的方式完全不可预测。无法知道应用程序接下来会请求哪个块,也无法知道它是否会再次访问以前的块。即使应用程序完全处理完其块,您也无法知道另一个应用程序是否会在不久的将来访问这些相同的块。本节将描述数据库引擎在这种情况下如何高效地管理内存。
4.4.1 缓冲区管理器 (The Buffer Manager)
缓冲区管理器 (buffer manager) 是数据库引擎中负责保存用户数据的页面的组件。缓冲区管理器分配一组固定数量的页面,称为缓冲区池 (buffer pool)。如本章开头所述,缓冲区池应适合计算机的物理内存,并且这些页面应来自操作系统持有的 I/O 缓冲区。
为了访问一个块,客户端根据 图 4.8 给出的协议与缓冲区管理器交互。
1. 客户端要求缓冲区管理器将缓冲区池中的一个页面固定到该块。
2. 客户端根据需要尽可能多地访问页面内容。
3. 当客户端使用完页面后,它会告诉缓冲区管理器解除固定该页面。
图 4.8 访问磁盘块的协议
如果某个客户端当前正在固定 (pinning) 一个页面,则称该页面已被固定 (pinned);否则,该页面是未固定 (unpinned) 的。缓冲区管理器有义务在页面被固定的时间内,始终为其客户端提供该页面。反之,一旦页面变为未固定状态,缓冲区管理器就可以将其分配给另一个块。
当客户端要求缓冲区管理器将页面固定到某个块时,缓冲区管理器会遇到以下四种情况之一:
- 块的内容位于缓冲区中的某个页面中,并且:
- 页面已固定。
- 页面未固定。
- 块的内容当前不在任何缓冲区中,并且:
- 缓冲区池中至少存在一个未固定的页面。
- 缓冲区池中的所有页面都已固定。
第一种情况发生在当前有一个或多个客户端正在访问块的内容时。由于一个页面可以被多个客户端固定,缓冲区管理器只需向该页面添加另一个固定,并将页面返回给客户端。每个固定该页面的客户端都可以自由地并发读取和修改其值。缓冲区管理器不关心可能发生的潜在冲突;这项职责属于第 5 章的并发管理器 (concurrency manager)。
第二种情况发生在使用缓冲区的客户端已完成使用,但缓冲区尚未重新分配时。由于块的内容仍在缓冲区页面中,缓冲区管理器可以通过简单地固定该页面并将其返回给客户端来重新利用该页面。
第三种情况要求缓冲区管理器将块从磁盘读入一个缓冲区页面。这涉及几个步骤。缓冲区管理器必须首先选择一个未固定的页面进行重用(因为已固定的页面仍被客户端使用)。其次,如果所选页面已被修改,则缓冲区管理器必须将页面内容写入磁盘;此操作称为刷新页面 (flushing the page)。最后,可以将请求的块读入所选页面,并且可以固定该页面。
第四种情况发生在缓冲区被大量使用时,例如第 14 章的查询处理算法中。在这种情况下,缓冲区管理器无法满足客户端请求。最佳解决方案是缓冲区管理器将客户端放入等待列表,直到有未固定的缓冲区页面可用。
4.4.2 缓冲区 (Buffers)
缓冲区池中的每个页面都具有相关的状态信息,例如它是否已固定,如果已固定,它被分配到哪个块。缓冲区 (buffer) 是包含此信息的对象。缓冲区池中的每个页面都有一个关联的缓冲区。每个缓冲区监视其页面的更改,并负责将其修改的页面写入磁盘。就像日志一样,如果缓冲区可以延迟写入其页面,则可以减少磁盘访问。例如,如果页面被修改多次,那么在所有修改完成后一次性写入页面会更高效。一个合理的策略是让缓冲区推迟将其页面写入磁盘,直到页面解除固定。
实际上,缓冲区可以等待更长的时间。假设一个修改过的页面解除固定但没有写入磁盘。如果该页面再次固定到同一个块(如上述第二种情况),客户端将看到与其离开时完全相同修改后的内容。这与页面已被写入磁盘然后又被读回的效果相同,但没有发生磁盘访问。从某种意义上说,缓冲区的页面充当其磁盘块的内存版本。任何希望使用该块的客户端都将被直接引导到缓冲区页面,客户端可以在不产生任何磁盘访问的情况下读取或修改该页面。
事实上,缓冲区只需要将修改过的页面写入磁盘的原因只有两个:要么页面被替换,因为缓冲区要固定到不同的块(如上述第三种情况),要么恢复管理器需要将其内容写入磁盘以防止可能发生的系统崩溃(将在第 5 章中讨论)。
4.4.3 缓冲区替换策略 (Buffer Replacement Strategies)
缓冲区池中的页面开始时是未分配的。随着固定请求的到来,缓冲区管理器通过将请求的块分配给未分配的页面来填充缓冲区池。一旦所有页面都已分配,缓冲区管理器将开始替换页面。缓冲区管理器可以选择缓冲区池中的任何未固定页面进行替换。
如果缓冲区管理器需要替换一个页面而所有缓冲区页面都已固定,则请求的客户端必须等待。因此,每个客户端都有责任“做一个好公民”,并在不再需要页面时尽快解除固定。
当有多个缓冲区页面未固定时,缓冲区管理器必须决定替换哪一个。这种选择可能对数据库系统的效率产生显著影响。例如,最糟糕的选择是替换下一个将被访问的页面,因为那样缓冲区管理器将不得不立即替换另一个页面。事实证明,最佳选择是始终替换将在最长时间内未使用的页面。
由于缓冲区管理器无法预测哪些页面将被访问,它被迫进行猜测。在这里,缓冲区管理器与操作系统在虚拟内存中交换页面时的情况几乎完全相同。然而,有一个很大的不同:与操作系统不同,缓冲区管理器知道一个页面当前是否正在使用,因为正在使用的页面正是被固定的页面。 无法替换已固定页面的负担反而变成了幸事。客户端通过负责任地固定页面,使缓冲区管理器避免做出真正糟糕的猜测。缓冲区替换策略只需要从当前不需要的页面中进行选择,这远不那么关键。
给定未固定页面的集合,缓冲区管理器需要决定这些页面中哪一个将在最长时间内不被需要。例如,数据库通常有一些页面(如第 7 章的目录文件)在数据库的整个生命周期中被持续使用。缓冲区管理器应避免替换这些页面,因为它们几乎肯定会很快被重新固定。
有几种替换策略试图做出最佳猜测。本节将考虑其中四种:朴素策略 (Naïve)、先进先出策略 (FIFO)、最近最少使用策略 (LRU) 和时钟策略 (Clock)。
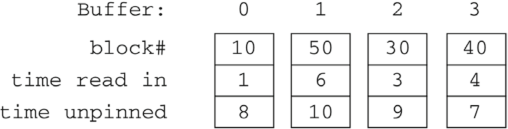
图 4.9 引入了一个示例,它将允许我们比较这些替换算法的行为。第 (a) 部分给出了一系列固定和解除固定文件五个块的操作,第 (b) 部分描绘了缓冲区池的最终状态,假设它包含四个缓冲区。唯一发生的页面替换是在第五个块(即块 50)被固定时。然而,由于当时只有一个缓冲区未固定,缓冲区管理器别无选择。换句话说,无论页面替换策略如何,缓冲区池都将如图 4.9b 所示。
pin(10); pin(20); pin(30); pin(40); unpin(20);
pin(50); unpin(40); unpin(10); unpin(30); unpin(50);
(a)
 (b)
(b)
图 4.9 一些固定/解除固定操作对四个缓冲区池的影响。(a) 十个固定/解除固定操作序列图 (b) 缓冲区池的最终状态
图 4.9b 中的每个缓冲区都包含三条信息:其块号、读入缓冲区的时间和解除固定的时间。图中的时间对应于图 4.9a 中操作的位置。
图 4.9b 中的所有缓冲区都处于未固定状态。现在假设缓冲区管理器收到另外两个固定请求:
pin(60); pin(70);
缓冲区管理器将需要替换两个缓冲区。所有缓冲区都可用;它应该选择哪一个?以下每种替换算法都会给出不同的答案。
朴素策略 (The Naïve Strategy)
最简单的替换策略是顺序遍历缓冲区池,替换找到的第一个未固定缓冲区。使用图 4.9 的示例,块 60 将分配给缓冲区 0,块 70 将分配给缓冲区 1。
这种策略易于实现,但几乎没有其他优点。例如,再次考虑图 4.9 的缓冲区,假设客户端重复固定和解除固定块 60 和 70,如下所示:
pin(60); unpin(60); pin(70); unpin(70); pin(60); unpin(60);...
朴素替换策略将对两个块都使用缓冲区 0,这意味着每次固定块时都需要从磁盘读取它们。问题是缓冲区池没有被均匀利用。如果替换策略为块 60 和 70 选择了两个不同的缓冲区,那么这些块将只从磁盘读取一次——这将大大提高效率。
先进先出策略 (The FIFO Strategy)
朴素策略只基于便利性选择缓冲区。FIFO 策略试图更智能,通过选择最近最少被替换的缓冲区,即在缓冲区池中停留时间最长的页面。这种策略通常比朴素策略效果更好,因为旧页面比最近获取的页面不太可能被需要。在图 4.9 中,最旧的页面是“读入时间”值最小的页面。因此,块 60 将分配给缓冲区 0,块 70 将分配给缓冲区 2。
FIFO 是一种合理的策略,但它并不总是做出正确的选择。例如,数据库通常有频繁使用的页面,例如第 7 章的目录页面。由于这些页面几乎被每个客户端使用,因此尽可能不替换它们是有意义的。然而,这些页面最终会成为池中最旧的页面,FIFO 策略将选择它们进行替换。
FIFO 替换策略可以通过两种方式实现。一种方式是让每个缓冲区都保存其页面上次被替换的时间,如图 4.9b 所示。然后替换算法将扫描缓冲区池,选择替换时间最早的未固定页面。第二种更有效的方式是让缓冲区管理器维护一个指向其缓冲区的指针列表,按替换时间排序。替换算法搜索列表;找到的第一个未固定页面被替换,并且指向它的指针被移动到列表的末尾。
最近最少使用策略 (The LRU Strategy)
FIFO 策略将其替换决策基于页面何时添加到缓冲区池。一个类似的策略是将决策基于页面最后一次访问的时间,理由是最近没有使用的页面在不久的将来也不会被使用。这种策略称为 LRU,代表最近最少使用 (least recently used)。在图 4.9 的示例中,“解除固定时间”值对应于缓冲区最后一次使用的时间。因此,块 60 将分配给缓冲区 3,块 70 将分配给缓冲区 0。
LRU 策略往往是一种有效的通用策略,并避免替换常用页面。FIFO 的两种实现选项都可以适应 LRU。唯一需要做的更改是,缓冲区管理器必须在每次页面解除固定时更新时间戳(对于第一个选项)或更新列表(对于第二个选项),而不是在页面被替换时。
时钟策略 (The Clock Strategy)
这种策略是上述策略的一种有趣的组合,其实现简单直观。与朴素策略一样,时钟替换算法扫描缓冲区池,选择它找到的第一个未固定页面。不同之处在于,算法总是从上次替换后的页面开始扫描。如果您将缓冲区池想象成一个圆形,那么替换算法就像模拟时钟的指针一样扫描池,在页面被替换时停止,并在需要另一次替换时重新开始。
图 4.9b 的示例没有指示时钟位置。但它上次替换的是缓冲区 1,这意味着时钟正好位于其之后。因此,块 60 将分配给缓冲区 2,块 70 将分配给缓冲区 3。
时钟策略试图尽可能均匀地使用缓冲区。如果一个页面被固定,时钟策略将跳过它,直到它检查了池中所有其他缓冲区后才会再次考虑它。此功能赋予该策略 LRU 特性。其思想是,如果一个页面被频繁使用,那么当轮到它被替换时,它很可能被固定。如果是这样,那么它就会被跳过并获得“另一次机会”。
4.5 SimpleDB 缓冲区管理器 (The SimpleDB Buffer Manager)
本节将探讨 SimpleDB 数据库系统的缓冲区管理器。第 4.5.1 节涵盖了缓冲区管理器的 API 并给出了其使用示例。第 4.5.2 节则展示了如何在 Java 中实现这些类。
4.5.1 缓冲区管理器的 API (An API for the Buffer Manager)
SimpleDB 缓冲区管理器由 simpledb.buffer 包实现。此包公开了两个类:BufferMgr 和 Buffer;它们的 API 如 图 4.10 所示。
// BufferMgr 类
public class BufferMgr {
// 构造函数:初始化 BufferMgr 对象
public BufferMgr(FileMgr fm, LogMgr lm, int numbuffs);
// 将指定块固定到缓冲区池中的一个页面,并返回该缓冲区对象
public Buffer pin(BlockId blk);
// 解除指定缓冲区的固定
public void unpin(Buffer buff);
// 返回当前未固定的缓冲区页面数量
public int available();
// 确保由指定事务修改的所有页面已写入磁盘
public void flushAll(int txnum);
}
// Buffer 类
public class Buffer {
// 构造函数:初始化 Buffer 对象
public Buffer(FileMgr fm, LogMgr lm);
// 返回缓冲区关联的 Page 对象
public Page contents();
// 返回缓冲区当前关联的 BlockId
public BlockId block();
// 检查缓冲区是否被固定
public boolean isPinned();
// 标记页面已修改,并记录修改事务号和日志序列号
public void setModified(int txnum, int lsn);
// 返回修改该页面的事务号
public int modifyingTx();
}
图 4.10 SimpleDB 缓冲区管理器的 API
每个数据库系统都有一个 BufferMgr 对象,它在系统启动时创建。其构造函数有三个参数:缓冲区池的大小,以及对文件管理器和日志管理器的引用。
BufferMgr 对象具有固定 (pin) 和解除固定 (unpin) 页面的方法。pin 方法返回一个固定到包含指定块的页面的 Buffer 对象,而 unpin 方法解除页面的固定。available 方法返回未固定的缓冲区页面数量。flushAll 方法确保由指定事务修改的所有页面都已写入磁盘。
给定一个 Buffer 对象,客户端可以调用其 contents 方法来获取关联的页面。如果客户端修改了页面,那么它还有责任生成适当的日志记录并调用缓冲区的 setModified 方法。该方法有两个参数:一个标识修改事务的整数和生成日志记录的 LSN。
图 4.11 中的代码测试了 Buffer 类。它第一次执行时打印“新值为 1”,后续每次执行都会使打印值递增。代码行为如下:它创建一个具有三个缓冲区的 SimpleDB 对象。它将一个页面固定到块 1,将偏移量 80 处的整数加 1,并调用 setModified 表示页面已被修改。setModified 的参数应该是事务号和生成的日志文件的 LSN。这两个值的细节将在第 5 章讨论,因此在此之前,给定的参数是合理的占位符。
public class BufferTest {
public static void main(String[] args) {
SimpleDB db = new SimpleDB("buffertest", 400, 3); // 创建一个 SimpleDB 实例,有 3 个缓冲区
BufferMgr bm = db.bufferMgr(); // 获取缓冲区管理器实例
// 第一次修改:固定块 1,修改,然后解除固定
Buffer buff1 = bm.pin(new BlockId("testfile", 1)); // 固定到 testfile 的块 1
Page p = buff1.contents(); // 获取页面内容
int n = p.getInt(80); // 读取偏移量 80 处的整数
p.setInt(80, n + 1); // 将其加 1
buff1.setModified(1, 0); // 标记页面已修改,事务号 1,LSN 0 (占位符)
System.out.println("新值是 " + (n + 1)); // 打印新值
bm.unpin(buff1); // 解除 buff1 的固定
// 引入新的固定操作,导致 buff1 被刷新到磁盘
// 缓冲区池大小为 3,现在 buff1 已经解除固定。
// 接下来固定块 2、3、4,会迫使 buff1 被替换并写入磁盘。
Buffer buff2 = bm.pin(new BlockId("testfile", 2));
Buffer buff3 = bm.pin(new BlockId("testfile", 3));
Buffer buff4 = bm.pin(new BlockId("testfile", 4)); // 这会触发 buff1 的写入
bm.unpin(buff2); // 解除 buff2 的固定
// 第二次修改:重新固定块 1,修改,但此次修改可能不会被写入磁盘
buff2 = bm.pin(new BlockId("testfile", 1)); // 再次固定块 1,可能重用了 buff1 之前的位置
Page p2 = buff2.contents();
p2.setInt(80, 9999); // 将值设置为 9999
buff2.setModified(1, 0); // 标记页面已修改,事务号 1,LSN 0 (占位符)
bm.unpin(buff2); // 解除 buff2 的固定
}
}
图 4.11 测试 Buffer 类
缓冲区管理器向其客户端隐藏了实际的磁盘访问。客户端不知道代表其发生了多少次磁盘访问以及何时发生。磁盘读取只能在调用 pin 期间发生——特别是当指定的块当前不在缓冲区中时。磁盘写入只能在调用 pin 或 flushAll 期间发生。如果被替换的页面已被修改,则调用 pin 将导致磁盘写入;调用 flushAll 将导致为指定事务修改的每个页面进行磁盘写入。
例如,图 4.11 的代码包含对块 1 的两次修改。这些修改都没有显式地写入磁盘。执行代码显示,第一次修改被写入磁盘,但第二次修改没有。
考虑第一次修改。由于缓冲区池中只有三个缓冲区,缓冲区管理器需要替换块 1 的页面(从而将其写入磁盘),以便为块 2、3 和 4 固定页面。另一方面,块 1 的页面在第二次修改后不需要被替换,因此该页面没有写入磁盘,其修改丢失了。丢失修改的问题将在第 5 章中讨论。
假设数据库引擎有很多客户端,所有客户端都在使用大量缓冲区。有可能所有缓冲区页面都被固定。在这种情况下,缓冲区管理器无法立即满足固定请求。相反,它会将客户端置于等待列表 (wait list)。当一个缓冲区可用时,缓冲区管理器会将客户端从等待列表中取出,以便它可以完成固定请求。换句话说,客户端不会意识到缓冲区争用;客户端只会注意到引擎似乎变慢了。
在一种情况下,缓冲区争用可能导致严重的问题。考虑一个场景,客户端 A 和 B 各需要两个缓冲区,但只有两个缓冲区可用。假设客户端 A 固定了第一个缓冲区。现在是争夺第二个缓冲区的竞争。如果客户端 A 在客户端 B 之前得到它,那么 B 将被添加到等待列表。客户端 A 最终会完成并解除固定缓冲区,届时客户端 B 可以固定它们。这是一个好的场景。现在假设客户端 B 在客户端 A 之前得到第二个缓冲区。那么 A 和 B 都将处于等待列表上。如果这是系统中仅有的两个客户端,那么将永远没有缓冲区被解除固定,A 和 B 都将永远处于等待列表上。这是一个坏的场景。客户端 A 和 B 被称为死锁 (deadlocked)。
在一个拥有数千个缓冲区和数百个客户端的真实数据库系统中,这种死锁的可能性很低。然而,缓冲区管理器必须准备好处理这种可能性。SimpleDB 采取的解决方案是跟踪客户端等待缓冲区的时间。如果等待时间过长(例如 10 秒),则缓冲区管理器假定客户端处于死锁状态并抛出 BufferAbortException 类型的异常。客户端负责处理该异常,通常通过回滚事务并可能重新启动事务。
图 4.12 中的代码测试了缓冲区管理器。它再次创建了一个只有三个缓冲区的 SimpleDB 对象,然后调用缓冲区管理器将其页面固定到文件“testfile”的块 0、1 和 2。然后它解除块 1 的固定,重新固定块 2,然后再次固定块 1。这三个操作不会导致任何磁盘读取,并且不会留下任何可用缓冲区。尝试固定块 3 将使线程进入等待列表。然而,由于该线程已经持有所有缓冲区,没有一个缓冲区会被解除固定,并且缓冲区管理器将在等待 10 秒后抛出异常。程序捕获异常并继续。它解除块 2 的固定。它尝试固定块 3 现在将成功,因为一个缓冲区已变得可用。
public class BufferMgrTest {
public static void main(String[] args) throws Exception {
SimpleDB db = new SimpleDB("buffermgrtest", 400, 3); // 创建一个 SimpleDB 实例,有 3 个缓冲区
BufferMgr bm = db.bufferMgr(); // 获取缓冲区管理器实例
Buffer[] buff = new Buffer[6]; // 声明一个 Buffer 数组
// 固定前三个块,耗尽所有缓冲区
buff[0] = bm.pin(new BlockId("testfile", 0));
buff[1] = bm.pin(new BlockId("testfile", 1));
buff[2] = bm.pin(new BlockId("testfile", 2));
// 解除 buff[1] 的固定,然后重新固定它(这不会释放缓冲区)
bm.unpin(buff[1]);
buff[1] = null; // 将其设为 null,以便后续可以重新分配
// 重新固定块 0 (已经固定) 和 1 (之前解除固定)
buff[3] = bm.pin(new BlockId("testfile", 0)); // 块 0 再次被固定 (增加 pin count)
buff[4] = bm.pin(new BlockId("testfile", 1)); // 块 1 再次被固定 (重用之前的缓冲区)
System.out.println("可用缓冲区: " + bm.available()); // 此时应该显示 0 个可用缓冲区 (所有都被固定)
try {
System.out.println("尝试固定块 3...");
// 此时所有缓冲区都已被固定 (块 0 被固定两次),所以固定块 3 会导致等待和死锁
buff[5] = bm.pin(new BlockId("testfile", 3));
} catch (BufferAbortException e) {
System.out.println("异常: 没有可用缓冲区\n"); // 捕获死锁异常
}
bm.unpin(buff[2]); // 解除 buff[2] 的固定,释放一个缓冲区
buff[2] = null;
// 再次尝试固定块 3,现在应该成功
buff[5] = bm.pin(new BlockId("testfile", 3)); // 现在这个操作成功了,因为有缓冲区可用了
System.out.println("最终缓冲区分配:");
for (int i = 0; i < buff.length; i++) {
Buffer b = buff[i];
if (b != null)
System.out.println("buff[" + i + "] 固定到块 " + b.block());
}
}
}
图 4.12 测试缓冲区管理器
4.5.2 实现缓冲区管理器 (Implementing the Buffer Manager)
图 4.13 包含了 Buffer 类的代码。一个 Buffer 对象跟踪其页面的四种信息:
- 对分配给其页面的块的引用。 如果没有分配块,则值为
null。 - 页面的固定次数。 每次固定时增加固定计数,每次解除固定时减少固定计数。
- 一个整数,指示页面是否已被修改。 值为 -1 表示页面未被更改;否则,该整数标识进行更改的事务。
- 日志信息。 如果页面已被修改,则缓冲区保存最新日志记录的 LSN。LSN 值永不为负。如果客户端调用
setModified时 LSN 为负,则表示该更新未生成日志记录。
public class Buffer {
private FileMgr fm; // 文件管理器实例
private LogMgr lm; // 日志管理器实例
private Page contents; // 缓冲区关联的页面内容
private BlockId blk = null; // 缓冲区当前关联的块 ID,如果未分配则为 null
private int pins = 0; // 该页面被固定的次数
private int txnum = -1; // 修改该页面的事务 ID,-1 表示未修改
private int lsn = -1; // 最近一次修改该页面对应的日志记录的 LSN,-1 表示没有日志记录
// 构造函数
public Buffer(FileMgr fm, LogMgr lm) {
this.fm = fm;
this.lm = lm;
contents = new Page(fm.blockSize()); // 初始化页面内容,大小为块大小
}
// 返回缓冲区关联的 Page 对象
public Page contents() {
return contents;
}
// 返回缓冲区当前关联的 BlockId
public BlockId block() {
return blk;
}
// 标记页面已修改
public void setModified(int txnum, int lsn) {
this.txnum = txnum; // 设置修改事务 ID
if (lsn >= 0) this.lsn = lsn; // 如果 LSN 有效,则设置 LSN
}
// 检查缓冲区是否被固定
public boolean isPinned() {
return pins > 0;
}
// 返回修改该页面的事务 ID
public int modifyingTx() {
return txnum;
}
// 将缓冲区分配给指定块
void assignToBlock(BlockId b) {
flush(); // 先刷新当前页面(如果已修改)
blk = b; // 设置新的块 ID
fm.read(blk, contents); // 从磁盘读取新块的内容到页面
pins = 0; // 重置固定计数
}
// 将页面内容刷新到磁盘
void flush() {
if (txnum >= 0) { // 如果页面已被修改 (txnum >= 0)
lm.flush(lsn); // 首先确保对应的日志记录已写入磁盘
fm.write(blk, contents); // 然后将页面内容写入磁盘
txnum = -1; // 重置事务 ID,表示页面已同步到磁盘
}
}
// 增加固定计数
void pin() {
pins++;
}
// 减少固定计数
void unpin() {
pins--;
}
}
图 4.13 SimpleDB 类 Buffer 的代码
flush 方法确保缓冲区的指定磁盘块与其页面具有相同的值。如果页面未被修改,则该方法无需执行任何操作。如果它已被修改,则该方法首先调用 LogMgr.flush 以确保相应的日志记录在磁盘上;然后它将页面写入磁盘。assignToBlock 方法将缓冲区与磁盘块关联起来。
缓冲区首先被刷新,以便保留对前一个块的任何修改。然后缓冲区与指定的块关联,从磁盘读取其内容。
BufferMgr 的代码如 图 4.14 所示。pin 方法将一个缓冲区分配给指定块。它通过调用私有方法 tryToPin 来完成。该方法分为两部分。第一部分 findExistingBuffer 尝试查找一个已经分配给指定块的缓冲区。如果找到,则返回该缓冲区。否则,算法的第二部分 chooseUnpinnedBuffer 使用朴素替换策略选择一个未固定的缓冲区。调用所选缓冲区的 assignToBlock 方法,该方法处理将现有页面写入磁盘(如果需要)以及从磁盘读取新页面。如果找不到未固定的缓冲区,该方法返回 null。
如果 tryToPin 返回 null,pin 方法将调用 Java 方法 wait。在 Java 中,每个对象都有一个等待列表。对象的 wait 方法会中断调用线程的执行并将其置于该列表上。在图 4.14 中,线程将一直停留在该列表上,直到发生以下两个条件之一:
- 另一个线程调用
notifyAll(这发生在调用unpin时)。 - 已过
MAX_TIME毫秒,这意味着线程等待时间过长。
当一个等待线程恢复时,它会继续其循环,尝试获取一个缓冲区(与所有其他等待线程一起)。该线程将不断被放回等待列表,直到它获得缓冲区或超出其时间限制。
unpin 方法解除指定缓冲区的固定,然后检查该缓冲区是否仍处于固定状态。如果不是,则调用 notifyAll 以从等待列表中移除所有客户端线程。这些线程将争夺缓冲区;哪个线程首先被调度,哪个线程就赢。当其他线程之一被调度时,它可能会发现所有缓冲区仍处于分配状态;如果是这样,它将被放回等待列表。
4.6 本章总结 (Chapter Summary)
- 数据库引擎必须努力最小化磁盘访问。因此,它仔细管理用于保存磁盘块的内存页面。管理这些页面的数据库组件是日志管理器和缓冲区管理器。
- 日志管理器负责将日志记录保存在日志文件中。由于日志记录总是追加到日志文件且永不修改,因此日志管理器可以非常高效。它只需要分配一个页面,并且有一个简单的算法来尽可能少地将该页面写入磁盘。
- 缓冲区管理器分配多个页面,称为缓冲区池,用于处理用户数据。缓冲区管理器根据客户端请求将缓冲区页面固定和解除固定到磁盘块。客户端在页面固定后访问缓冲区页面,并在完成后解除固定缓冲区。
- 已修改的缓冲区将在两种情况下写入磁盘:当页面被替换时,以及当恢复管理器需要它在磁盘上时。
public class BufferMgr {
private Buffer[] bufferpool; // 缓冲区池,存储 Buffer 对象的数组
private int numAvailable; // 当前可用(未固定)的缓冲区数量
private static final long MAX_TIME = 10000; // 线程等待缓冲区的最大时间,10 秒
// 构造函数:初始化缓冲区管理器
public BufferMgr(FileMgr fm, LogMgr lm, int numbuffs) {
bufferpool = new Buffer[numbuffs]; // 创建指定大小的缓冲区池
numAvailable = numbuffs; // 初始时所有缓冲区都可用
for (int i = 0; i < numbuffs; i++)
bufferpool[i] = new Buffer(fm, lm); // 初始化每个 Buffer 对象
}
// 获取当前可用缓冲区的数量(同步方法)
public synchronized int available() {
return numAvailable;
}
// 刷新所有由指定事务修改的页面到磁盘(同步方法)
public synchronized void flushAll(int txnum) {
for (Buffer buff : bufferpool)
if (buff.modifyingTx() == txnum) // 如果缓冲区被该事务修改过
buff.flush(); // 刷新该缓冲区
}
// 解除指定缓冲区的固定(同步方法)
public synchronized void unpin(Buffer buff) {
buff.unpin(); // 减少缓冲区的固定计数
if (!buff.isPinned()) { // 如果缓冲区不再被固定
numAvailable++; // 增加可用缓冲区计数
notifyAll(); // 通知所有等待缓冲区的线程
}
}
// 将指定块固定到缓冲区并返回对应的 Buffer 对象(同步方法)
public synchronized Buffer pin(BlockId blk) {
try {
long timestamp = System.currentTimeMillis(); // 记录开始等待时间
Buffer buff = tryToPin(blk); // 尝试固定缓冲区
// 如果没有找到可用缓冲区且未超时,则等待
while (buff == null && !waitingTooLong(timestamp)) {
wait(MAX_TIME); // 等待 MAX_TIME 毫秒或被 notifyAll 唤醒
buff = tryToPin(blk); // 再次尝试固定缓冲区
}
if (buff == null) // 如果最终仍未找到可用缓冲区
throw new BufferAbortException(); // 抛出异常
return buff; // 返回固定成功的缓冲区
} catch (InterruptedException e) {
throw new BufferAbortException(); // 处理中断异常
}
}
// 检查等待时间是否过长
private boolean waitingTooLong(long starttime) {
return System.currentTimeMillis() - starttime > MAX_TIME;
}
// 尝试固定缓冲区
private Buffer tryToPin(BlockId blk) {
Buffer buff = findExistingBuffer(blk); // 尝试查找已存在的缓冲区
if (buff == null) { // 如果不存在
buff = chooseUnpinnedBuffer(); // 选择一个未固定的缓冲区进行替换 (当前使用朴素策略)
if (buff == null)
return null; // 如果没有未固定的缓冲区,则返回 null
buff.assignToBlock(blk); // 将新块分配给选定的缓冲区
}
if (!buff.isPinned()) // 如果缓冲区之前没有被固定
numAvailable--; // 减少可用缓冲区计数
buff.pin(); // 增加缓冲区的固定计数
return buff; // 返回缓冲区
}
// 查找已存在并与指定块关联的缓冲区
private Buffer findExistingBuffer(BlockId blk) {
for (Buffer buff : bufferpool) {
BlockId b = buff.block();
if (b != null && b.equals(blk)) // 如果缓冲区关联的块 ID 与请求的块 ID 相同
return buff; // 返回该缓冲区
}
return null; // 未找到
}
// 选择一个未固定的缓冲区(当前使用朴素策略:找到第一个未固定的)
private Buffer chooseUnpinnedBuffer() {
for (Buffer buff : bufferpool)
if (!buff.isPinned()) // 如果缓冲区未被固定
return buff; // 返回该缓冲区
return null; // 未找到未固定的缓冲区
}
}
图 4.14 SimpleDB 类 BufferMgr 的代码
-
当客户端请求将页面固定到某个块时,缓冲区管理器会选择适当的缓冲区。如果该块的页面已在某个缓冲区中,则使用该缓冲区;否则,缓冲区管理器会替换现有缓冲区的内容。
-
决定替换哪个缓冲区的算法称为
缓冲区替换策略
。四种有趣的替换策略是:
- 朴素策略 (Naïve):选择找到的第一个未固定缓冲区。
- 先进先出策略 (FIFO):选择内容最近最少被替换的未固定缓冲区。
- 最近最少使用策略 (LRU):选择内容最近最少被解除固定的未固定缓冲区。
- 时钟策略 (Clock):从上次替换的缓冲区开始顺序扫描缓冲区;选择找到的第一个未固定缓冲区。
4.7 建议阅读 (Suggested Reading)
Effelsberg 等人 (1984) 的文章对缓冲区管理进行了详尽而全面的论述,扩展了本章中的许多思想。Gray 和 Reuter (1993) 的第 13 章深入讨论了缓冲区管理,并以典型的缓冲区管理器的基于 C 的实现为例进行阐述。
Oracle 的默认缓冲区替换策略是 LRU。然而,在扫描大表时,它使用 FIFO 替换。理由是表扫描通常在页面解除固定后不再需要该块,因此 LRU 最终会保存错误的块。详细信息可在 Ashdown 等人 (2019) 的第 14 章中找到。
一些研究人员已经研究了如何使缓冲区管理器本身更智能。基本思想是缓冲区管理器可以跟踪每个事务的固定请求。如果它检测到某种模式(例如,事务重复读取文件的相同 N 个块),即使这些页面没有被固定,它也会尝试避免替换这些页面。Ng 等人 (1991) 的文章更详细地描述了这一思想并提供了一些模拟结果。
- Ashdown, L., et al. (2019). Oracle database concepts. Document E96138-01,Oracle Corporation. 可从 Oracle在线文档 获取。
- Effelsberg, W., & Haerder, T. (1984). Principles of database buffer management.ACM Transactions on Database Systems, 9(4), 560–595.
- Gray, J., & Reuter, A. (1993). Transaction processing: concepts and techniques.Morgan Kaufman.
- Ng, R., Faloutsos, C., & Sellis, T. (1991). Flexible buffer allocation based on marginal gains. Proceedings of the ACM SIGMOD Conference, pp. 387–396.
4.8 练习 (Exercises)
概念性练习 (Conceptual Exercises)
4.1. LogMgr.iterator 的代码调用了 flush。这个调用是必要的吗?请解释。
4.2. 解释为什么 BufferMgr.pin 方法是同步的。如果它不是同步的,可能会出现什么问题?
4.3. 是否有多个缓冲区可以分配给同一个块?请解释。
4.4. 本章中的缓冲区替换策略在寻找可用缓冲区时,没有区分已修改和未修改的页面。一个可能的改进是,缓冲区管理器在可能的情况下总是替换未修改的页面。
(a) 给出一个理由说明为什么这个建议可以减少缓冲区管理器进行的磁盘访问次数。
(b) 给出一个理由说明为什么这个建议可以增加缓冲区管理器进行的磁盘访问次数。
(c) 您认为这个策略值得吗?请解释。
4.5. 另一种可能的缓冲区替换策略是最近最少修改 (least recently modified):缓冲区管理器选择具有最低 LSN 的已修改缓冲区。解释为什么这种策略可能值得。
4.6. 假设一个缓冲区页面已被修改多次但尚未写入磁盘。缓冲区只保存最近一次更改的 LSN,并在页面最终被刷新时只将这个 LSN 发送给日志管理器。解释为什么缓冲区不需要将其他 LSN 发送给日志管理器。
4.7. 考虑图 4.9a 的示例固定/解除固定场景,以及附加操作 pin(60); pin(70)。对于文本中给出的四种替换策略,假设缓冲区池包含五个缓冲区,绘制出缓冲区的状态。
4.8. 从图 4.9b 的缓冲区状态开始,给出一个场景,其中:
(a) FIFO 策略需要的磁盘访问次数最少。
(b) LRU 策略需要的磁盘访问次数最少。
(c) 时钟策略需要的磁盘访问次数最少。
4.9. 假设两个不同的客户端都想固定同一个块,但由于没有可用缓冲区而被置于等待列表。考虑 SimpleDB 类 BufferMgr 的实现。展示当单个缓冲区可用时,两个客户端都将能够使用它。
4.10. 考虑谚语“虚拟是其自身的奖赏 (Virtual is its own reward)。”评论这个双关语的巧妙之处,并讨论它对缓冲区管理器的适用性。
编程练习 (Programming Exercises)
4.11. SimpleDB 日志管理器分配自己的页面并明确地将其写入磁盘。另一个设计选项是让它将一个缓冲区固定到最后一个日志块,并让缓冲区管理器处理磁盘访问。
(a) 设计这个选项。需要解决哪些问题?这是一个好主意吗?
(b) 修改 SimpleDB 以实现您的设计。
4.12. 每个 LogIterator 对象都分配一个页面来保存它访问的日志块。
(a) 解释为什么使用缓冲区而不是页面会更有效率。
(b) 修改代码以使用缓冲区而不是页面。缓冲区应该如何解除固定?
4.13. 本练习探讨 JDBC 程序是否可以恶意固定缓冲区池中的所有缓冲区。
(a) 编写一个 JDBC 程序来固定 SimpleDB 缓冲区池中的所有缓冲区。当所有缓冲区都被固定时会发生什么?
(b) Derby 数据库系统与 SimpleDB 的缓冲区管理方式不同。当 JDBC 客户端请求一个缓冲区时,Derby 会固定该缓冲区,将该缓冲区的副本发送给客户端,然后解除固定该缓冲区。解释为什么您的代码对其他 Derby 客户端不会是恶意的。
(c) Derby 通过始终将页面从引擎复制到客户端来避免 SimpleDB 的问题。解释这种方法的后果。您更喜欢它还是 SimpleDB 的方法?
(d) 阻止恶意客户端独占所有缓冲区的另一种方法是允许每个事务固定不超过缓冲区池的某个百分比(例如,10%)。实现并测试对 SimpleDB 缓冲区管理器的此修改。
4.14. 修改 BufferMgr 类以实现本章中描述的其他每种替换策略。
4.15. 练习 4.4 建议了一种页面替换策略,即优先选择未修改的页面而不是已修改的页面。实现此替换策略。
4.16. 练习 4.5 建议了一种页面替换策略,即选择 LSN 最低的已修改页面。实现此策略。
4.17. SimpleDB 缓冲区管理器在搜索缓冲区时顺序遍历缓冲区池。当池中有数千个缓冲区时,这种搜索将非常耗时。修改代码,添加数据结构(例如专用列表和哈希表)以提高搜索时间。
4.18. 在练习 3.15 中,您被要求编写代码来维护磁盘使用情况的统计信息。扩展此代码以提供缓冲区使用情况的信息。