数据库系统(Database System)
数据库系统在计算机行业中扮演着重要的角色。一些数据库系统(例如 Oracle)是极其复杂的,通常运行在大型高端机器上。另一些(例如 SQLite)则小巧、精简,旨在存储特定于应用程序的数据。尽管它们用途广泛,但所有数据库系统都具有相似的功能。本章将探讨数据库系统必须解决的问题及其应具备的能力。它还将介绍本书中将讨论的 Derby 和 SimpleDB 数据库系统。
1.1 为什么要使用数据库系统? (Why a Database System?)
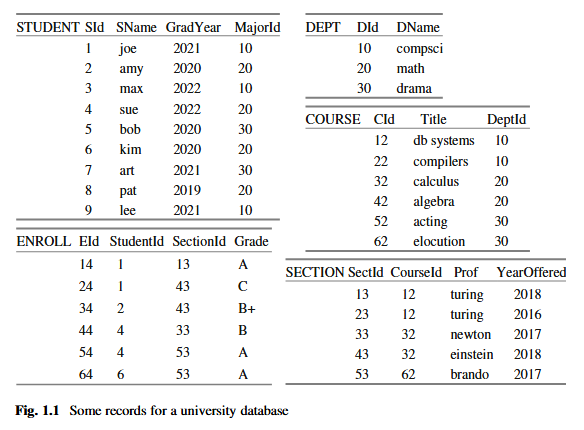
数据库是存储在计算机上的数据集合。数据库中的数据通常组织成记录,例如员工记录、医疗记录、销售记录等。图 1.1 描绘了一个数据库,其中包含大学学生及其所修课程的信息。该数据库将作为本书贯穿始终的示例。图 1.1 的数据库包含五种类型的记录:
- STUDENT 记录:记录每位曾就读于该大学的学生。每条记录包含学生的 ID 号、姓名、毕业年份和学生主修系的 ID。
- DEPT 记录:记录大学中的每个系。每条记录包含系的 ID 号和名称。
- COURSE 记录:记录大学提供的每门课程。每条记录包含课程的 ID 号、标题以及开设该课程的系的 ID。
- SECTION 记录:记录每门课程中曾开设的每个班级。每条记录包含班级的 ID 号、开设班级的年份、课程的 ID 以及教授该班级的教授。
- ENROLL 记录:记录学生选修的每门课程。每条记录包含选课 ID 号、学生和所修课程班级的 ID 号,以及学生在该课程中获得的成绩。
图 1.1 只是这些记录的概念性图片。它没有说明记录如何存储或如何访问。有许多可用的软件产品,称为数据库系统,它们提供了一整套用于管理记录的功能。
“管理”记录意味着什么?数据库系统必须具备哪些功能,哪些功能是可选的?以下五个要求似乎是根本性的:
- 数据库必须是持久的。 否则,一旦计算机关闭,记录就会消失。
- 数据库可以共享。 许多数据库,例如我们的大学数据库,旨在由多个并发用户共享。
- 数据库必须保持准确。 如果用户无法信任数据库的内容,它就会变得毫无用处和价值。
- 数据库可能非常庞大。 图 1.1 的数据库只包含 29 条记录,这小得可笑。数据库包含数百万(甚至数十亿)条记录并不少见。
- 数据库必须可用。 如果用户无法轻松获取他们想要的数据,他们的生产力就会受到影响,他们就会吵着要不同的产品。
以下小节将探讨这些要求的影响。每个要求都迫使数据库系统包含越来越多的功能,导致其复杂性超出您的预期。
1.1.1 记录存储 (Record Storage)
使数据库持久化的一种常见方法是将其记录存储在文件中。最简单直接的方法是数据库系统将记录存储在文本文件中,每种记录类型一个文件;每条记录可以是一行文本,其值用制表符分隔。图 1.2 描绘了 STUDENT 记录文本文件的开头。
这种方法的好处是用户可以用文本编辑器检查和修改文件。不幸的是,这种方法效率太低,无法派上用场,原因有二。
第一个原因是大型文本文件更新时间过长。例如,假设有人从 STUDENT 文件中删除了 Joe 的记录。数据库系统别无选择,只能重写从 Amy 记录开始的文件,将每个后续记录向左移动。尽管重写一个小文件所需的时间可以忽略不计,但重写一个 1 GB 的文件很容易花费几分钟,这是不可接受的长时间。数据库系统需要更巧妙地存储记录,以便文件更新只需要小型、局部的重写。
第二个原因是大型文本文件读取时间过长。考虑在 STUDENT 文件中搜索 2019 届的学生。唯一的方法是顺序扫描文件。顺序扫描效率可能非常低。您可能知道几种内存中的数据结构,例如树和哈希表,它们可以实现快速搜索。数据库系统需要使用类似的数据结构来实现其文件。例如,数据库系统可能会使用一种结构来组织文件中的记录,以方便某种特定类型的搜索(例如,按学生姓名、毕业年份或专业),或者它可能会创建多个辅助文件,每个文件都方便不同类型的搜索。这些辅助文件称为索引,是第 12 章的主题。
1.1.2 多用户访问 (Multi-user Access)
当许多用户共享一个数据库时,他们很可能会并发访问其某些数据文件。并发性是件好事,因为每个用户都可以快速得到服务,而无需等待其他用户完成。但是过多的并发性是不好的,因为它可能导致数据库变得不准确。例如,考虑一个旅行规划数据库。假设两个用户试图预订一个还有 40 个座位的航班。如果两个用户并发读取相同的航班记录,他们都会看到 40 个可用座位。然后他们都修改记录,使航班现在有 39 个可用座位。糟糕!两个座位已被预订,但数据库中只记录了一个预订。
解决这个问题的方法是限制并发性。数据库系统应该允许第一个用户读取航班记录并看到 40 个可用座位,然后阻塞第二个用户,直到第一个用户完成。当第二个用户恢复时,它将看到 39 个可用座位并将其修改为 38,这是正确的。通常,数据库系统必须能够检测到用户何时即将执行与另一个用户的操作冲突的动作,然后(并且仅在此时)阻止该用户执行,直到第一个用户完成。
用户可能还需要撤消他们所做的数据库更新。例如,假设用户在旅行规划数据库中搜索马德里的行程,并找到了一个有可用航班和有空房酒店的日期。现在假设用户预订了航班,但在预订过程中,该日期的所有酒店都住满了。在这种情况下,用户可能需要撤消航班预订并尝试不同的日期。
不可撤消的更新不应该对数据库的其他用户可见。否则,另一个用户可能会看到更新,认为数据是“真实”的,并根据它做出决定。因此,数据库系统必须为用户提供指定其更改何时永久化的能力;用户被认为提交了更改。一旦用户提交,更改就会变得可见且无法撤消。第 5 章将探讨这些问题。
1.1.3 处理灾难 (Dealing with Catastrophe)
假设您正在运行一个程序,为所有教授加薪,此时数据库系统意外崩溃。系统重启后,您发现有些教授的工资更新了,但有些没有。您该怎么办?您不能仅仅重新运行程序,因为那样会导致一些教授获得双倍加薪。相反,您需要数据库系统能够从崩溃中优雅地恢复,撤消崩溃发生时所有正在运行的程序的更新。这样做的机制很有趣且不简单,将在第 5 章中探讨。
1.1.4 内存管理 (Memory Management)
数据库需要存储在持久内存中,例如磁盘驱动器或闪存驱动器。闪存驱动器比磁盘驱动器快约 100 倍,但也贵得多。典型的访问时间,磁盘约为 6 毫秒,闪存约为 60 微秒。然而,这两个时间都比主内存(或 RAM)慢几个数量级,RAM 的访问时间约为 60 纳秒。也就是说,RAM 比闪存快约 1000 倍,比磁盘快 100,000 倍。
为了了解这种性能差异的影响以及数据库系统面临的随之而来的问题,请考虑以下类比。假设您想吃一块巧克力曲奇饼。有三种获取方式:从您厨房、从附近杂货店或通过邮购。在这个类比中,您的厨房对应 RAM,附近商店对应闪存驱动器,邮购公司对应磁盘。假设从您的厨房拿到曲奇饼需要 5 秒。从类比商店拿到曲奇饼将需要 5000 秒,超过一小时。这意味着要去商店,排很长的队,买曲奇饼,然后返回。从类比邮购公司拿到曲奇饼将需要 500,000 秒,超过 5 天。这意味着在线订购曲奇饼并使用标准交付方式运输。从这个角度来看,闪存和磁盘内存看起来非常慢。
等等!情况更糟。数据库对并发性和可靠性的支持会使事情变得更慢。如果其他人正在使用您想要的数据,那么您可能被迫等待直到数据被释放。在我们的类比中,这对应于到达杂货店,发现曲奇饼卖完了,迫使您等到它们补货。
换句话说,数据库系统面临以下难题:它必须管理比主内存系统更多的数据,使用更慢的设备,多个人争夺数据的访问权,并且使其完全可恢复,同时还要保持合理的响应时间。
解决这个难题的很大一部分是使用缓存。每当数据库系统需要处理一条记录时,它都会将其加载到 RAM 中并尽可能长时间地保留在那里。因此,主内存将包含当前正在使用的数据库部分。所有读写都发生在 RAM 中。这种策略的优点是使用快速的主内存而不是慢速的持久内存,但缺点是数据库的持久版本可能会过时。数据库系统需要实现技术来使数据库的持久版本与 RAM 版本保持同步,即使在系统崩溃(RAM 内容被销毁时)的情况下也是如此。第 4 章将探讨各种缓存策略。
1.1.5 可用性 (Usability)
如果用户无法轻松提取他们想要的数据,数据库就没什么用。例如,假设用户想知道所有 2019 年毕业学生的姓名。在没有数据库系统的情况下,用户将被迫编写一个程序来扫描学生文件。图 1.3 给出了这样一个程序的 Java 代码,假设文件以文本形式存储。请注意,大多数 Java 代码都在处理文件解码、读取每条记录并将其拆分为要检查的值数组。用于确定所需学生姓名(粗体显示)的代码隐藏在无趣的文件操作代码中。
public static List<String> getStudents2019() {
List<String> result = new ArrayList<>();
FileReader rdr = new FileReader("students.txt");
BufferedReader br = new BufferedReader(rdr);
String line = br.readLine();
while (line != null) {
String[] vals = line.split("\t");
String gradyear = vals[2];
if (gradyear.equals("2019"))
result.add(vals[1]);
line = br.readLine();
}
return result;
}
因此,大多数数据库系统都支持查询语言,以便用户可以轻松指定他们想要的数据。关系数据库的标准查询语言是 SQL。图 1.3 的代码可以用一个 SQL 语句来表达:
select SName from STUDENT where GradYear = 2019
这个 SQL 语句比 Java 程序短得多、清晰得多,主要是因为它指定了要从文件中提取的值,而无需指定如何检索它们。
1.2 Derby 数据库系统 (The Derby Database System)
如果你能交互式地使用数据库系统来学习数据库概念,效果会好得多。尽管有各种各样的数据库系统可用,我建议你使用 Derby 数据库系统,因为它基于 Java,免费,易于安装且易于使用。最新版本的 Derby 可以从 db.apache.org/derby 的下载选项卡中下载。下载的发布文件解压后会得到一个包含多个目录的文件夹。例如,docs 目录包含参考文档,demo 目录包含示例数据库等等。整个系统包含的功能远不止这里能涵盖的;感兴趣的读者可以仔细阅读 docs 目录中的各种指南和手册。
Derby 有许多本书不需要的功能。事实上,你只需要将 Derby 的 lib 目录中的四个文件添加到你的类路径中:derby.jar、derbynet.jar、derbyclient.jar 和 derbytools.jar。更改类路径的方法有很多种,具体取决于你的 Java 平台和操作系统。我将解释如何使用 Eclipse 开发平台进行操作。如果你不熟悉 Eclipse,可以从 eclipse.org 下载其代码和文档。如果你使用不同的开发平台,你应该能够调整我的 Eclipse 指南以适应你的环境。
首先,为 Derby 创建一个 Eclipse 项目。然后按如下方式配置其构建路径:从“属性”窗口中,选择“Java 构建路径”。点击“库”选项卡,然后点击“添加外部 JAR”,并使用文件选择器选择你需要的四个 jar 文件。就是这样。
Derby 发布版包含一个名为 ij 的应用程序,它使你能够创建和访问 Derby 数据库。因为 Derby 完全用 Java 编写,所以 ij 实际上是 Java 类 org.apache.derby.tools 包中的一个名称。你通过执行它的类来运行 ij。要从 Eclipse 执行该类,请转到“运行”菜单中的“运行配置”。为你的 Derby 项目添加一个新的配置;将其命名为“Derby ij”。在配置主类的字段中,输入“org.apache.derby.tools.ij”。当你运行该配置时,ij 将显示一个控制台窗口,要求输入。
ij 的输入是一系列命令。命令是一个以分号结尾的字符串。命令可以分成几行文本;ij 客户端直到遇到以分号结尾的行才会执行命令。任何 SQL 语句都是合法的命令。此外,ij 支持连接和断开数据库以及退出会话的命令。
connect 命令指定 ij 应该连接到的数据库,disconnect 命令断开连接。一个给定的会话可以多次连接和断开。exit 命令结束会话。图 1.4 展示了一个 ij 会话示例。该会话分为两部分。在第一部分中,用户连接到一个新数据库,创建了一个表,向该表中插入了一条记录,然后断开连接。在第二部分中,用户重新连接到该数据库,检索插入的值,然后断开连接。
ij> connect 'jdbc:derby:ijtest;create=true';
ij> create table T(A int, B varchar(9));
0 rows inserted/updated/deleted
ij> insert into T(A,B) values(3, 'record3');
1 row inserted/updated/deleted
ij> disconnect;
ij> connect 'jdbc:derby:ijtest';
ij> select * from T;
A |B
---------------------
3 |record3
1 row selected
ij> disconnect;
ij> exit;
图 1.4 一个 ij 会话示例
connect 命令的参数称为其连接字符串。连接字符串有三个子字符串,由冒号分隔。前两个子字符串是“jdbc”和“derby”,表示你想使用 JDBC 协议连接到 Derby 数据库。(JDBC 是第 2 章的主题。)第三个子字符串标识数据库。字符串“ijtest”是数据库的名称;它的文件将位于一个名为“ijtest”的文件夹中,该文件夹位于启动 ij 程序的目录中。例如,如果你从 Eclipse 运行程序,数据库文件夹将位于项目目录中。字符串“create = true”告诉 Derby 创建一个新的数据库;如果省略它(如在第二个连接命令中),那么 Derby 将期望找到一个现有数据库。
1.3 数据库引擎 (Database Engines)
像 ij 这样的数据库应用程序由两个独立的部分组成:用户界面 (UI) 和访问数据库的代码。后一部分代码称为数据库引擎。将 UI 与数据库引擎分离是良好的系统设计,因为它简化了应用程序的开发。这种分离的一个著名例子出现在 Microsoft Access 数据库系统中。它有一个图形 UI,允许用户通过点击鼠标和填写值与数据库交互,还有一个处理数据存储的引擎。当 UI 确定它需要数据库中的信息时,它会构建一个请求并将其发送给引擎。然后引擎执行请求并将值发送回 UI。
这种分离还增加了系统的灵活性:应用程序设计人员可以使用相同的用户界面与不同的数据库引擎,或者为相同的数据库引擎构建不同的用户界面。Microsoft Access 为每种情况都提供了一个示例。使用 Access UI 构建的表单可以连接到 Access 引擎或任何其他数据库引擎。Excel 电子表格中的单元格可以包含查询 Access 引擎的公式。
UI 通过连接到所需的引擎,然后调用引擎 API 中的方法来访问数据库。例如,请注意 Derby ij 程序实际上只是一个 UI。它的 connect 命令建立与指定数据库引擎的连接,每个 SQL 命令将 SQL 语句发送到引擎,检索结果并显示它们。
数据库引擎通常支持多种标准 API。当 Java 程序连接到引擎时,首选的 API 称为 JDBC。第 2 章详细讨论 JDBC,并展示如何使用 JDBC 编写类似 ij 的应用程序。
从 UI 到数据库引擎的连接可以是嵌入式或基于服务器的。在嵌入式连接中,数据库引擎的代码与 UI 的代码在同一个进程中运行,这使得 UI 独占访问引擎。只有当数据库“属于”该应用程序并且存储在与应用程序相同的机器上时,应用程序才应该使用嵌入式连接。其他应用程序需要使用基于服务器的连接。
在基于服务器的连接中,数据库引擎的代码在专用的服务器程序内部执行。这个服务器程序始终在运行,等待客户端连接,并且不需要与客户端在同一台机器上。客户端与服务器建立连接后,客户端向服务器发送 JDBC 请求并接收响应。
一个服务器可以同时连接到多个客户端。当服务器处理一个客户端的请求时,其他客户端可以发送自己的请求。服务器包含一个调度器,它将等待服务的请求排队,并确定它们何时执行。每个客户端都不知道其他客户端,并且(除了由于调度引起的延迟之外)愉快地认为服务器正在独占地处理它。
图 1.4 的 ij 会话使用了嵌入式连接。它在运行会话的机器上创建了数据库“ijtest”,并且没有涉及服务器。要执行类似的基于服务器的 ij 会话,必须更改两件事:Derby 引擎必须作为服务器运行,并且 connect 命令必须修改以标识服务器。
Derby 服务器的代码在 Java 类 NetworkServerControl 中,位于 org.apache.derby.drda 包中。要从 Eclipse 运行服务器,请转到“运行”菜单中的“运行配置”。为你的 Derby 项目添加一个新的配置,并将其命名为“Derby Server”。在主类的字段中,输入“org.apache.derby.drda.NetworkServerControl”。在“参数”选项卡中,输入程序参数“start -h localhost”。每次运行配置时,都会出现一个控制台窗口,指示 Derby 服务器正在运行。
程序参数“start -h localhost”的目的是什么?第一个词是命令“start”,它告诉该类启动服务器。你可以通过使用参数“shutdown”执行相同的类来停止服务器(或者你可以直接从控制台窗口终止进程)。字符串“-h localhost”告诉服务器只接受来自同一机器上客户端的请求。如果你将“localhost”替换为域名或 IP 地址,那么服务器将只接受来自该机器的请求。使用 IP 地址“0.0.0.0”告诉服务器接受来自任何地方的请求。
基于服务器的连接的连接字符串必须指定服务器机器的网络或 IP 地址。特别是,请考虑以下 ij 连接命令:
ij> connect 'jdbc:derby:ijtest'ij> connect 'jdbc:derby://localhost/ijtest'ij> connect 'jdbc:derby://cs.bc.edu/ijtest'
第一个命令建立与“ijtest”数据库的嵌入式连接。第二个命令使用在“localhost”机器(即本地机器)上运行的服务器建立与“ijtest”的基于服务器的连接。第三个命令使用在“cs.bc.edu”机器上运行的服务器建立与“ijtest”的基于服务器的连接。
请注意 connect 字符串如何完全封装了使用嵌入式或服务器端连接的决定。例如,再次考虑图 1.4。你可以通过简单地更改 connect 命令来修改会话,使其使用服务器端连接而不是嵌入式连接。会话中的其他命令不受影响。
1.4 SimpleDB 数据库系统 (The SimpleDB Database System)
Derby 是一个复杂、功能齐全的数据库系统。然而,这种复杂性意味着它的源代码不容易理解或修改。我编写 SimpleDB 数据库系统是为了与 Derby 相反——它的代码小巧、易读且易于修改。它省略了所有不必要的功能,只实现了 SQL 的一小部分,并且只使用了最简单(且通常非常不实用)的算法。它的目的是让你清楚地了解数据库引擎的每个组件以及这些组件如何交互。
最新版本的 SimpleDB 可以从其网站 cs.bc.edu/~sciore/simpledb 下载。下载的文件会解压到 SimpleDB_3.x 文件夹;该文件夹包含 simpledb、simpleclient 和 derbyclient 目录。simpledb 文件夹包含数据库引擎的代码。与 Derby 不同,此代码未打包成 jar 文件;相反,每个文件都明确地位于文件夹中。
要安装 SimpleDB 引擎,您必须将 simpledb 文件夹添加到您的类路径中。要使用 Eclipse 执行此操作,首先,创建一个新项目;将其命名为“SimpleDB Engine”。然后从操作系统中,将 SimpleDB_3.x 文件夹中名为“simpledb”的子文件夹复制到项目的 src 文件夹中。最后,使用文件菜单中的刷新命令从 Eclipse 刷新项目。
derbyclient 文件夹包含调用 Derby 引擎的示例程序。使用操作系统将此文件夹的内容(而不是文件夹本身)复制到您的 Derby 项目的 src 文件夹中,并刷新它。这些客户端程序将在第 2 章中讨论。
simpleclient 文件夹包含调用 SimpleDB 引擎的示例程序。您应该为它们创建一个新项目;将其命名为“SimpleDB Clients”。为了确保示例程序能够找到 SimpleDB 引擎代码,您应该将 SimpleDB Engine 项目添加到 SimpleDB Clients 的构建路径中。然后使用操作系统将 simpleclient 的内容复制到 SimpleDB Clients 的 src 目录中。
SimpleDB 支持嵌入式和基于服务器的连接。simpleclient 文件夹中的程序之一是 SimpleIJ,它是 Derby ij 程序的简化版本。与 ij 的一个不同之处在于,您只能在会话开始时连接一次。当您执行程序时,它会要求您输入连接字符串。连接字符串的语法与 ij 中的类似。例如,考虑以下 SimpleDB 连接字符串:
jdbc:simpledb:testijjdbc:simpledb://localhostjdbc:simpledb://cs.bc.edu
第一个连接字符串指定到“testij”数据库的嵌入式连接。与 Derby 一样,数据库将位于执行程序的目录中,即 SimpleDB Clients 项目中。与 Derby 不同,如果数据库不存在,SimpleDB 将创建数据库,因此不需要显式的“create = true”标志。
第二个和第三个连接字符串指定到在本地机器或 cs.bc.edu 上运行的 SimpleDB 服务器的基于服务器的连接。与 Derby 不同,连接字符串不指定数据库。原因是 SimpleDB 引擎一次只能处理一个数据库,该数据库在服务器启动时指定。
SimpleIJ 会重复打印提示符,要求您输入一行包含 SQL 语句的文本。与 Derby 不同,该行必须包含整个语句,并且末尾不需要分号。然后程序执行该语句。如果语句是查询,则显示输出表。如果语句是更新命令,则打印受影响的记录数。如果语句格式不正确,则会打印错误消息。SimpleDB 仅理解 SQL 的一个非常有限的子集,如果给定引擎不理解的 SQL 语句,SimpleIJ 将抛出异常。这些限制将在下一节中描述。
SimpleDB 引擎可以作为服务器运行。主类是 simpledb.server 包中的 StartServer。要从 Eclipse 运行服务器,请转到“运行”菜单中的“运行配置”。为您的 SimpleDB Engine 项目添加一个名为“SimpleDB Server”的新配置。在主类的字段中,输入“simpledb.server.StartServer”。使用“参数”选项卡输入所需数据库的名称。为方便起见,如果您省略参数,服务器将使用名为“studentdb”的数据库。当您运行配置时,应出现一个控制台窗口,指示 SimpleDB 服务器正在运行。
SimpleDB 服务器接受来自任何地方的客户端连接,对应于 Derby 的“-h 0.0.0.0”命令行选项。关闭服务器的唯一方法是从控制台窗口终止其进程。
1.5 SimpleDB 版本的 SQL (The SimpleDB Version of SQL)
Derby 实现了几乎所有标准 SQL。另一方面,SimpleDB 只实现了标准 SQL 的一个微小子集,并施加了 SQL 标准中不存在的限制。本节简要说明这些限制。本书的其他章节将更详细地解释它们,并且许多章节末尾的练习将要求您实现一些被省略的功能。
SimpleDB 中的查询仅包含 select-from-where 子句,其中 select 子句包含字段名列表(没有 AS 关键字),from 子句包含表名列表(没有范围变量)。
可选的 where 子句中的术语只能通过布尔运算符 and 连接。术语只能比较常量和字段名的相等性。与标准 SQL 不同,没有其他比较运算符、其他布尔运算符、算术运算符或内置函数,也没有括号。因此,不支持嵌套查询、聚合和计算值。
因为没有范围变量和没有重命名,查询中的所有字段名必须是不相交的。并且因为没有 group by 或 order by 子句,所以不支持分组和排序。其他限制是:
select子句中的“*”缩写不被支持。- 没有空值。
from子句中没有显式连接或外连接。union关键字不被支持。insert语句只接受显式值。也就是说,插入不能由查询指定。update语句的set子句中只能有一个赋值。
1.6 章总结 (Chapter Summary)
- 数据库是存储在计算机上的数据集合。数据库中的数据通常组织成记录。数据库系统是管理数据库中记录的软件。
- 数据库系统必须能够处理大型共享数据库,将其数据存储在慢速持久内存中。它必须提供其数据的高级接口,并确保在面对冲突的用户更新和系统崩溃时的数据准确性。
- 数据库系统通过具有以下功能来满足这些要求:
- 能够以比文件系统通常允许的更有效的方式存储记录的文件。
- 用于文件中数据索引的复杂算法,以支持快速访问。
- 能够处理来自多个用户的并发访问,必要时阻塞用户。
- 支持提交和回滚更改。
- 能够将数据库记录缓存到主内存中,并管理数据库的持久版本和主内存版本之间的同步,如果系统崩溃,则将数据库恢复到合理的状态。
- 语言编译器/解释器,用于将用户对表的查询转换为对文件的可执行代码。
- 查询优化策略,用于将低效查询转换为更高效的查询。
- 数据库引擎是数据库系统中维护数据的组件。数据库应用程序负责用户输入和输出;它调用数据库引擎以获取所需数据。
- 与数据库引擎的连接可以是嵌入式或基于服务器的。具有嵌入式连接的程序独占访问数据库引擎。具有基于服务器连接的程序与其他并发程序共享引擎。
- Derby 和 SimpleDB 是两个基于 Java 的数据库系统。Derby 实现了完整的 SQL 标准,而 SimpleDB 只实现了 SQL 的有限子集。SimpleDB 很有用,因为它的代码易于理解。本书的其余部分将从第 3 章开始详细探讨此代码。
1.7 建议阅读 (Suggested Reading)
数据库系统多年来经历了巨大的变化。关于这些变化的详细描述可以在 National Research Council (1999) 的第 6 章和 Haigh (2006) 中找到。en.wikipedia.org/wiki/Database_management_system#History 上的维基百科条目也很有趣。
客户端-服务器范式在计算的许多领域都很有用,不仅仅是数据库。该领域的一般概述可以在 Orfali et al. (1999) 中找到。Derby 服务器各种功能和配置选项的文档可以在 db.apache.org/derby/manuals/index.html 找到。
- Haigh, T. (2006). “A veritable bucket of facts”. Origins of the data base management system. ACM SIGMOD Record, 35(2), 33–49.
- National Research Council Committee on Innovations in Computing and Communications. (1999). Funding a revolution. National Academy Press. Available from
www.nap.edu/read/6323/chapter/8#159 - Orfali, R., Harkey, D., & Edwards, J. (1999). Client/server survival guide (3rd ed.). Wiley.
1.8 练习 (Exercises)
概念性练习 (Conceptual Exercises)
1.1. 假设一个组织需要管理相对少量(例如,100 条左右)的共享记录。
(a) 使用商业数据库系统来管理这些记录有意义吗?
(b) 哪些数据库系统的功能是不需要的?
(c) 使用电子表格来存储这些记录合理吗?潜在问题是什么?
1.2. 假设您想在数据库中存储大量个人数据。您不需要哪些数据库系统的功能?
1.3. 考虑您通常不使用数据库系统管理的一些数据(例如购物清单、地址簿、支票账户信息等)。
(a) 数据需要多大才会让您不得不将其存储在数据库系统中?
(b) 您使用数据的方式需要进行哪些更改,才能使其值得使用数据库系统?
1.4. 如果您知道如何使用版本控制系统(例如 Git 或 Subversion),请将其功能与数据库系统的功能进行比较。
(a) 版本控制系统有记录的概念吗?
(b) 签入/签出如何对应数据库并发控制?
(c) 用户如何执行提交?用户如何撤消未提交的更改?
(d) 许多版本控制系统将更新保存在差异文件中,这些文件是很小的文件,描述了如何将文件的先前版本转换为新版本。如果用户需要查看文件的当前版本,系统会从原始文件开始并对其应用所有差异文件。这种实现策略如何满足数据库系统的需求?
基于项目的练习 (Project-Based Exercises)
1.5. 调查您的学校管理部门或公司是否使用数据库系统。如果是:
(a) 哪些员工在工作中明确使用数据库系统?(与那些运行使用数据库但他们不知情的“预设”程序的员工不同。)他们用它来做什么?
(b) 当用户需要对数据进行新操作时,是用户自己编写查询,还是由其他人来做?
1.6. 安装并运行 Derby 和 SimpleDB 服务器。
(a) 在服务器机器上运行 ij 和 SimpleIJ 程序。
(b) 如果您可以访问第二台机器,请修改演示客户端并从该机器远程运行它们。